
谷歌搜索控制台可以让你通过谷歌的眼睛查看你的网站。
您可以获得有关网站性能的信息,以及有关页面体验、安全问题、爬网或索引的详细信息。
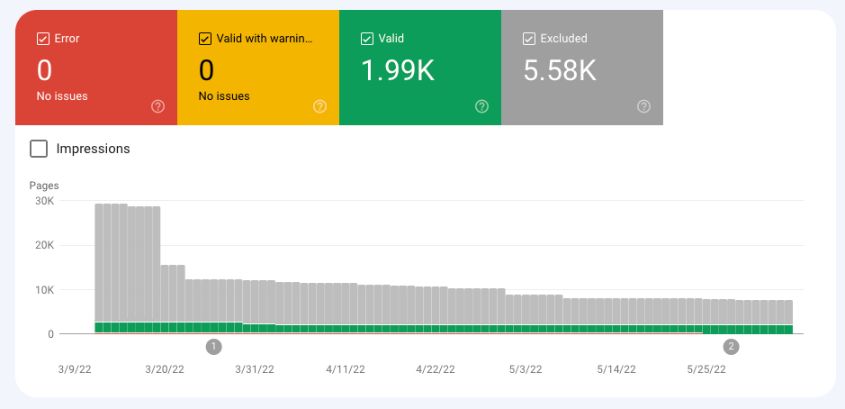
谷歌搜索控制台索引覆盖率报告的排除部分提供了有关网站页面索引状态的信息。
了解为什么您网站的某些页面会出现在谷歌搜索控制台的排除报告中,以及如何修复。
什么是索引覆盖率报告?
谷歌搜索控制台覆盖率报告显示了有关网站网页索引状态的详细信息。
您的网页可以进入以下四个桶之一:
- 错误:Google无法索引的页面。您应该查看此报告,因为Google认为您可能希望这些页面被索引。
- 有效警告:Google索引的页面,但有一些问题需要解决。
- 有效:Google索引的页面。
- 排除:从索引中排除的页面。
什么是排除页面?
谷歌不索引错误和排除桶中的页面。
两者之间的主要区别是:
- 谷歌认为有错误的页面应该被索引,但不能,因为一个你应该检查的错误。例如,通过XML站点地图提交的不可索引页面属于错误。
- 谷歌认为被排除的页面确实应该被排除,这是你的意图。例如,非索引
未提交给谷歌的xable页面将出现在排除报告中。谷歌搜索控制台截图,2022年5月
然而,谷歌并不总是正确的,应该被索引的页面有时会被排除。
幸运的是,Google搜索控制台提供了将页面放置在特定bucket中的原因。
这就是为什么仔细查看所有四个bucket中的页面是一个很好的做法。
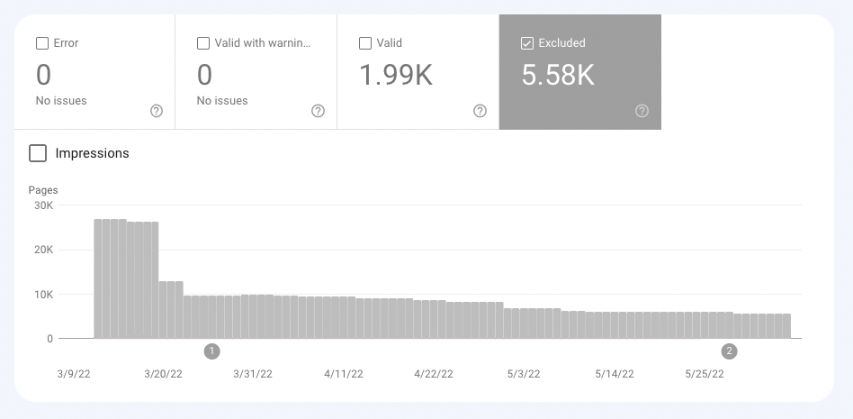
现在让我们深入到排除的桶中。
排除页面的可能原因
您的网页被排除在排除组中有15种可能的原因。让我们仔细看看每一个。
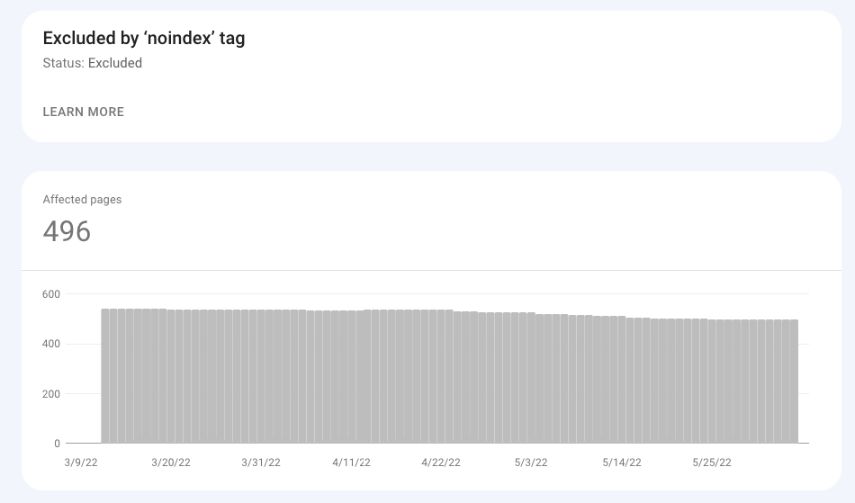
被“noindex”标签排除
这些URL具有“noindex”标记。
Google认为您实际上想要将这些页面从索引中排除,因为您没有在XML站点地图中列出它们。
例如,这些可以是登录页面、用户页面或搜索结果页面。
建议的行动:
- 查看这些URL,确保您想将其从Google索引中排除。
- 检查这些URL上是否仍然\/实际存在“noindex”标记。
已爬网–当前未索引
谷歌已经抓取了这些页面,但仍然没有为它们编制索引。
正如谷歌在其文档中所说,这个bucket中的URL“将来可能会或可能不会被索引;无需重新提交该URL进行爬网。”
许多搜索引擎优化专家注意到,如果许多正常和可索引的页面被爬网——目前没有索引——网站可能会有一些严重的质量问题。
这可能意味着谷歌已经抓取了这些页面,并且认为它们没有提供足够的价值来索引。
谷歌搜索控制台截图,2022年5月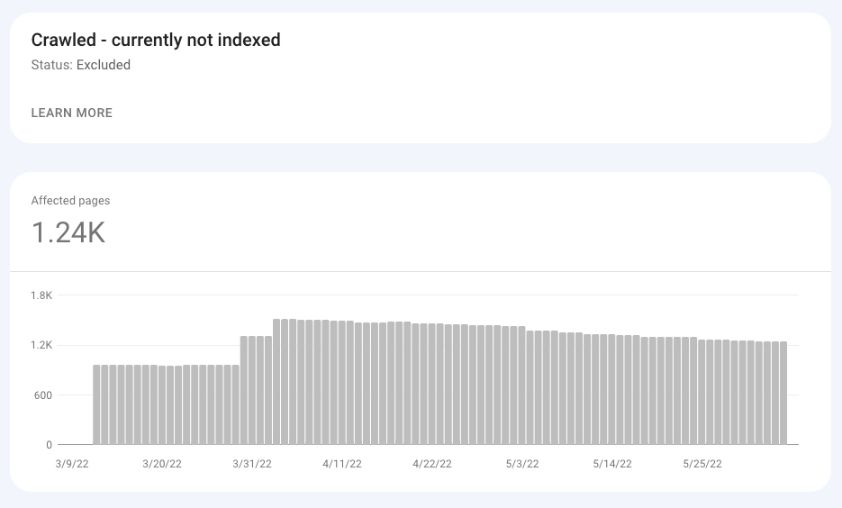
建议的行动:
- 回顾您的we
B现场质量和E-A-T方面。
已发现–当前未索引
正如谷歌文档所说,被发现的页面——目前还没有被索引——“被谷歌发现,但还没有被抓取。”
谷歌没有抓取页面,以免服务器过载。此bucket下的大量页面可能意味着您的站点存在爬网预算问题。
谷歌搜索控制台截图,2022年5月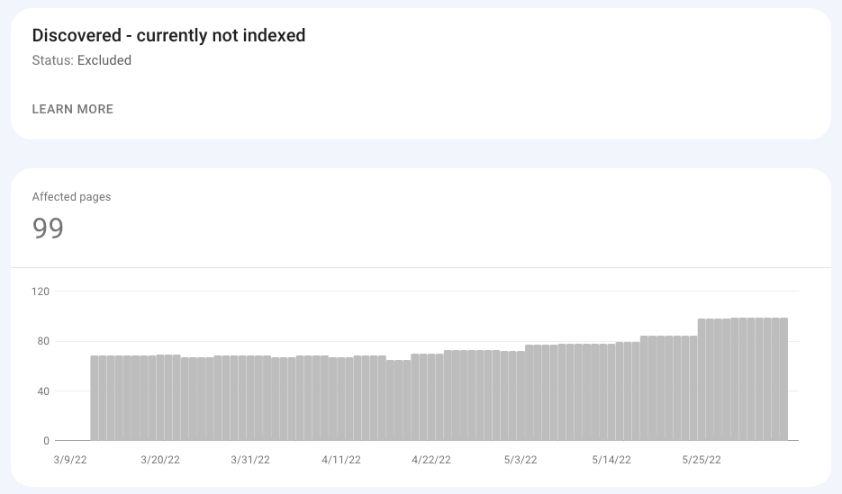
建议的行动:
- 检查服务器的运行状况。
未找到(404)
这些页面在Google请求时返回状态代码404(未找到)。
这些不是提交给谷歌的URL(即,在XML站点地图中),而是谷歌发现了这些页面(即,通过另一个链接到很久以前删除的旧页面的网站)。
谷歌搜索控制台截图,2022年5月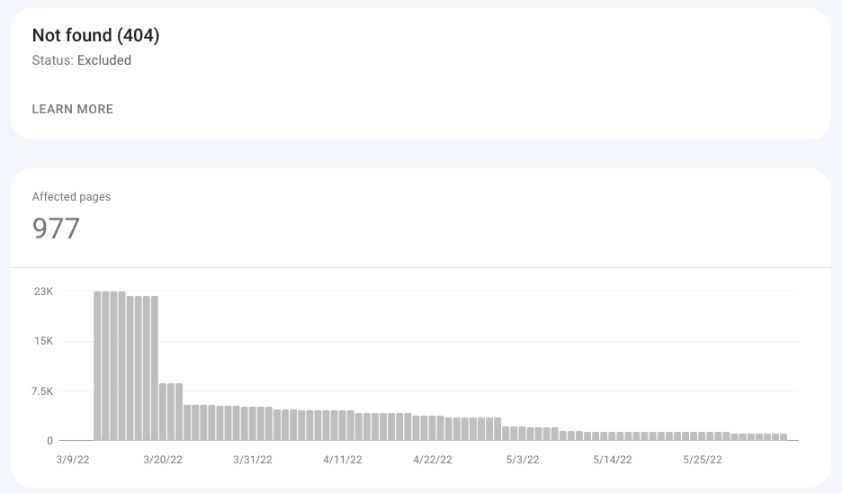
建议的行动:
- 查看这些页面并决定是否实现301重定向到工作页面。
软404
在大多数情况下,软404是返回状态代码OK(200)的错误页面。
或者,它也可以是一个很薄的页面,包含很少或没有内容,并使用“对不起”、“错误”、“找不到”等词。
谷歌搜索控制台截图,2022年5月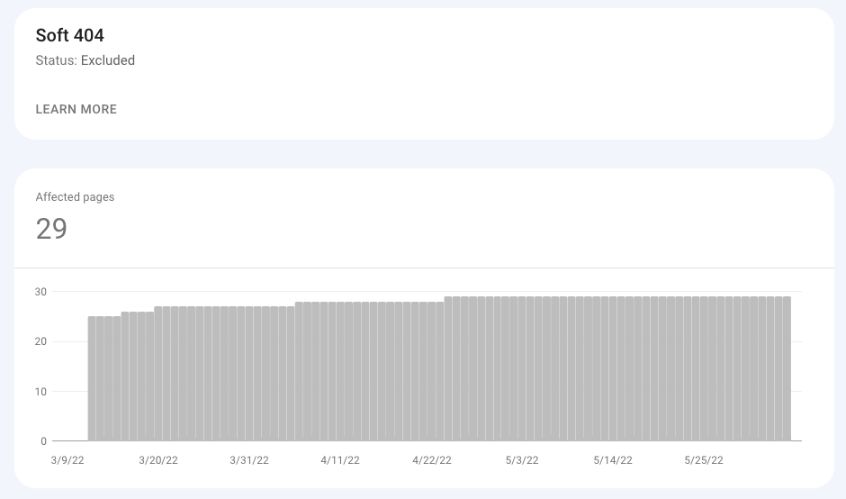
建议的行动:
- 如果出现错误页面,请确保返回状态代码404。
- 对于薄c
内容页面,添加独特的内容以帮助Google将此URL识别为独立页面。
带重定向的页面
您网站上的所有重定向页面将转到排除的bucket,在那里您可以看到Google在您网站上检测到的所有重定向页。
谷歌搜索控制台截图,2022年5月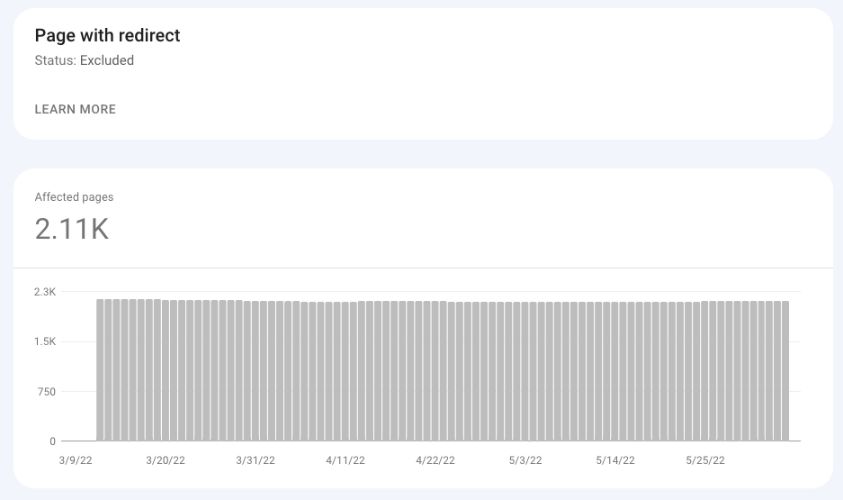
建议的行动:
- 查看重定向页面,以确保重定向是有意实现的。
- 有些WordPress插件会在您更改URL时自动创建重定向,因此您可能需要偶尔查看这些。
没有用户选择的复制规范
谷歌认为这些URL与您网站上的其他URL重复,因此不应编制索引。
您没有为这些URL设置规范标记,Google根据其他信号选择了规范标记。
建议的行动:
- 检查这些URL以检查Google为这些页面选择了哪些规范URL。
为了复制,Google选择了与用户不同的Canonical
谷歌搜索控制台截图,2022年5月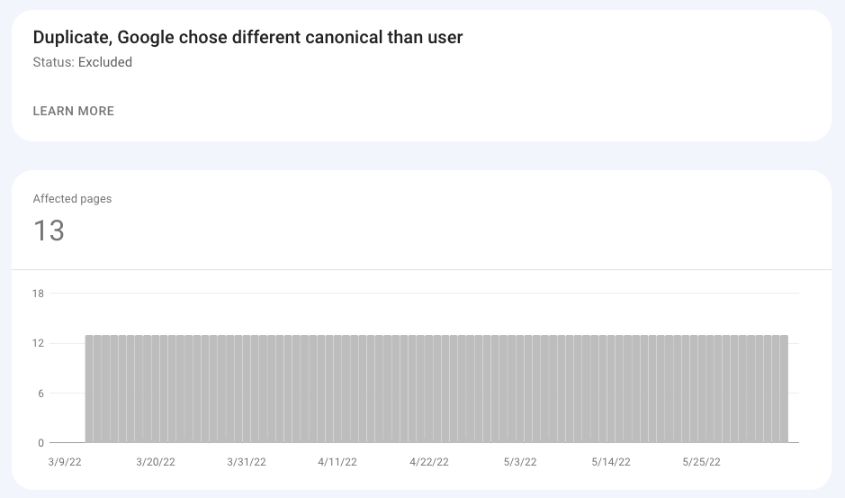
在本例中,您为页面声明了一个规范URL,但即使如此,Google还是选择了一个不同的URL作为规范URL。因此,Google选择的规范被索引,而用户选择的规范没有索引。
可能采取的行动:
- 检查URL以检查什么是佳能
ical和Google被选中。 - 分析可能导致谷歌选择不同规范(即外部链接)的信号。
重复,提交的URL未选择为规范
上述状态与此状态之间的区别在于,在后一种情况下,您向Google提交了一个URL进行索引化,而没有声明其规范地址,Google认为不同的URL会使其更规范。
因此,Google选择的canonical被索引,而不是提交的URL。
建议的行动:
- 检查URL以检查canonical Google选择了什么。
具有适当规范标记的备用页
这些只是Google识别为规范URL的页面的副本。
这些页面具有指向正确规范URL的规范地址。
建议的行动:
- 在大多数情况下,不需要采取任何行动。
被Robots.txt阻止
这些是机器人的页面。txt已被阻止。
在分析这个bucket时,请记住,如果Google在其他网站上找到这些页面的引用,Google仍然可以索引这些页面(并以“受损”的方式显示它们)。
建议的行动:
- 使用机器人验证这些页面是否被阻止。txt测试仪。
- 添加“noindex”标记并从机器人中删除页面。txt,如果您想从索引中删除它们。
被页面删除工具阻止
此报告列出了删除工具请求删除的页面。
请记住,此工具仅临时(90天)从搜索结果中删除页面,不会从索引中删除页面。
建议的行动:
- 验证通过删除工具提交的页面是否应临时删除或具有“noindex”标记。
由于未授权请求而被阻止(401)
在这些URL的情况下,由于授权请求(401状态代码),Googlebot无法访问页面。
除非这些页面在未经授权的情况下可用,否则您无需执行任何操作。
谷歌只是告诉你它遇到了什么。
谷歌搜索控制台截图,2022年5月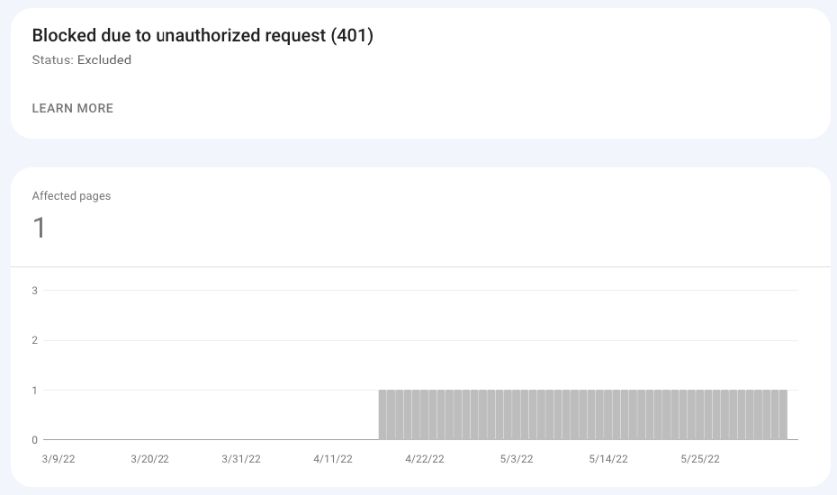
建议的行动:
- 验证这些页面是否实际需要授权。
由于访问被禁止而被阻止(403)
此状态代码通常是服务器错误的结果。
当提供的凭据不正确,并且无法授予对页面的访问权限时,返回403。
正如谷歌文档所述:
“Googlebot从不提供凭据,因此您的服务器错误地返回了此错误。此错误应该得到修复,或者页面应该被robots.txt或noindex阻止。”
您可以从排除的页面中学到什么?
被排除页面的特定桶中的突然和巨大峰值可能表明严重的站点问题。
以下是三个可能表明您的网站存在严重问题的峰值示例:
- 未找到(404)页面中的巨大峰值可能表示URL已更改的迁移不成功,但红色
新地址的指令尚未实现。这也可能发生在,例如,一个没有经验的人改变了博客文章的片段,结果改变了所有博客的URL。 - 发现的数据(当前未索引或未爬网)中的巨大峰值可能表明您的站点已被黑客入侵。确保查看示例页面,以检查这些页面是否实际上是您的页面,或者是由于黑客攻击而创建的(即带有中文字符的页面)。
- “noindex”标签排除的巨大峰值也可能表示启动和迁移不成功。当一个新站点与来自临时站点的“noindex”标记一起投入生产时,通常会发生这种情况。
重述
由于GSC覆盖率报告中的排除部分,您可以了解很多关于您的网站以及Googlebot如何与之交互的信息。
无论你是一个新的搜索引擎优化或已经有几年的经验,让它成为你的日常习惯,检查谷歌搜索控制台。
这可以帮助您在各种技术SEO问题变成真正的灾难之前发现它们。



