关于新的谷歌算法更新有很多炒作和错误信息。BERT 究竟是什么,它是如何工作的,为什么它对我们作为谷歌 SEO 的工作很重要?加入我们自己的机器学习和自然语言处理专家布兰妮·穆勒(Britney Muller)的行列,她将详细分析 BERT 是什么以及它对搜索行业的意义。

单击上面的白板图像,在新标签页中打开高分辨率版本!
视频转录
嘿,莫兹的粉丝。欢迎来到另一版 Whiteboard Friday。今天我们谈论的是 BERT 的所有事情,我非常兴奋地尝试为每个人真正分解它。我不声称自己是 BERT 专家,但我已经做了很多很多的研究。–我已经能够采访到该领域的一些专家,我的目标是尝试成为这些信息更容易理解的催化剂。
围绕 BERT 以及您如何无法针对它进行优化的行业目前正在发生大量骚动。虽然这是绝对正确的,但您不能,您只需要为您的用户编写非常好的内容,我仍然认为我们中的许多人进入这个领域是因为我们天生好奇。如果你想了解更多关于 BERT 的知识,并且能够更好地向客户解释它,或者围绕 BERT 的背景进行更好的对话,那么我希望你喜欢这个视频。如果没有,而且这不适合你,那也没关系。
警告:不要过度炒作 BERT!
我很高兴能马上加入。我想提到的第一件事是我能够与自然语言处理研究员 Allyson Ettinger 坐下来。她是芝加哥大学的教授,也是最善良的人之一。非常感谢她花时间和我聊聊 BERT。
我一起吃午饭的主要收获是,不要过度宣传 BERT,这一点非常非常重要。现在有很多骚动,但距离我们人类能够理解的语言和上下文还很远。所以我认为重要的是要记住,我们并没有过分强调这个模型可以做什么,但它仍然非常令人兴奋,它是 NLP 和机器学习的一个非常具有里程碑意义的时刻。事不宜迟,让我们直接进入。
BERT 是从哪里来的?
我想给每个人一个更广泛的背景,了解 BERT 的来源和发展方向。我认为很多时候这些公告是对谷歌搜索引擎优化行业投下的炸弹,本质上是一系列电影中的静止画面,但没有完整的前后电影片段。我们只是得到这个静止的帧。所以我们得到了这个 BERT 公告,但让我们回到过去一点。
自然语言处理
传统上,计算机理解语言的时间是不可能的。它们可以存储文本,我们可以输入文本,但是对于计算机而言,语言的理解一直是非常困难的。自然语言处理 (NLP) 随之而来,研究人员在该领域开发独特的模型来解决特定类型的语言理解问题。几个例子是;命名实体识别、分类、情感分析和问答。
所有这些传统上都是通过适合解决一项特定语言任务的单个模型来解决的,所以它看起来有点像你的厨房:
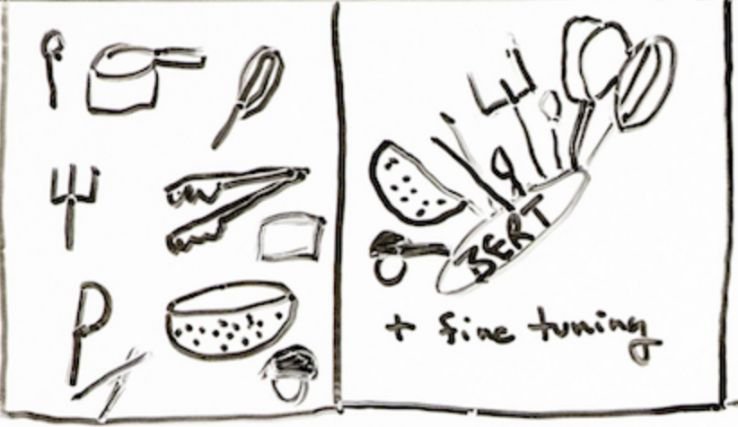
想想你厨房里的餐具等单独的 NLP 模型,它们都有一项非常具体的任务,而且做得很好。
现在考虑一个万能的厨房用具,它是您最常用的 11 个用具合二为一。这就是 BERT,它是一款厨房用具,在经过微调后,它确实非常非常好地完成了 11 种顶级自然语言处理解决方案。
NLP 领域令人兴奋的差异化。这就是为什么人们对此感到非常兴奋,因为他们不再需要所有单独的模型。——他们可以使用 BERT 来解决大多数 NLP 任务,谷歌将 BERT 纳入谷歌的算法是有道理的。
BERT 去哪儿了?
这个标题在哪里?这是要去哪里?艾莉森曾说过,
“我认为我们将在一段时间内沿着相同的轨迹前进,构建更大更好的 BERT 变体,这些变体在 BERT 强大的方式上更强大,并且可能具有相同的基本限制。”
已经有大量不同版本的 BERT,我们将继续看到越来越多的版本。看看这个空间的走向会很有趣。
BERT 是如何变得如此聪明的?
我们来看看一个非常简单的关于 BERT 是如何变得如此聪明的观点如何?
谷歌将维基百科文本和大量资金用于计算能力(他们将 TPU 放在一个 V3 吊舱中),这些计算能力可以为这些大型模型提供动力。然后,他们使用无监督神经网络从维基百科的所有文本中进行训练,以更好地理解语言和上下文。
它的学习方式的有趣之处在于,它采用任意长度的文本(这很好,因为语言在我们说话的方式中非常随意)并将其转录成向量。
向量是一串固定的数字。这有助于语言可以翻译成机器。
这发生在我们甚至无法想象的非常狂野的 n 维空间中。将相似的上下文语言放入相同的区域。
为了让 BERT 变得越来越聪明,类似于 Word2vec,使用了一种称为掩码的策略。

当句子中的随机词被隐藏时,就会发生掩蔽。
BERT 是一个双向模型,它查看隐藏词之前和之后的词,以帮助预测该词是什么。
它一遍又一遍地这样做,直到它在预测蒙面单词方面变得强大。然后可以进一步对其进行微调,以完成 11 种最常见的自然语言处理任务。在这个空间里,真的,真的很令人兴奋,也很有趣。
什么是 BERT?
BERT 是一种预训练的无监督自然语言处理模型。BERT 在微调后可以胜过 11 种最常见的 NLP 任务,本质上成为自然语言处理和理解的火箭助推器。
BERT 是深度双向的,这意味着它查看在 Wikipedia 上预训练的实体和上下文之前和之后的单词,以提供对语言的更丰富的理解。
查看此 Whiteboard Friday,了解有关什么是无监督模型的更多背景信息。
BERT 不能做的事情有哪些?
Allyson Ettinger 写了一篇非常棒的研究论文,名为 What BERT Can’t Do。从她的研究中最令人惊讶的收获是否定诊断领域,这意味着 BERT 不太擅长理解否定或不是什么东西。

例如,当输入一个 Robin 时是一个……它预测了鸟,这是对的,这很好。但是当进入一个知更鸟不是一个……它还预测鸟。因此,在 BERT 没有看到否定示例或上下文的情况下,它仍然很难理解这一点。在 Allyson 的研究中还有很多非常有趣的内容,强烈建议您查看一下。
您如何针对 BERT 进行优化?(你不能!)
最后,您如何针对 BERT 进行优化?再说一次,你不能。通过此更新改进您的网站的唯一方法是为您的用户编写非常棒的内容并实现他们所寻求的意图。
Briggsby 的 On-page google SEO for NLP 文章是帮助您更好地理解和编写 NLP 的一个很好的资源。
谷歌在自然问题理解方面不断增长的能力
我不得不提的一件事是 Google 的 Jeff Dean 的主题演讲,因为老实说我无法忘记这一点。他在谈论 BERT,然后进入自然问题和自然问题理解。对我来说最大的收获是这个例子,好吧,假设有人问了这个问题,“你可以在飞行模式下拨打和接听电话吗?”

来自 Jeff Dean 的深度学习解决重要问题主题演讲的截图。
谷歌的自然语言翻译层试图理解所有这些文本的文本块非常技术性且难以理解:
飞行模式、飞行模式、飞行模式、离线模式或独立模式是许多智能手机、便携式计算机和其他电子设备上可用的设置,激活后会暂停设备的射频信号传输,从而禁用蓝牙、电话和无线网络。GPS 可能会或可能不会被禁用,因为它不涉及传输无线电波。
通过这些层,并利用 BERT 之类的东西,他们能够从所有这些非常复杂、冗长、令人困惑的语言中回答“不”。它在我们的领域非常非常强大。
考虑诸如精选片段之类的事情;考虑诸如 SERP 功能之类的事情。我的意思是,这可能会开始对我们的空间产生巨大的影响。所以我认为重要的是要了解它的发展方向以及该领域正在发生的事情。
我真的希望你喜欢这个版本的 Whiteboard Friday。如果您在下面有任何问题或意见,请告诉我,我期待下次再见。非常感谢。
Speechpad.com 的视频转录



