我是一个自筹资金的初创企业主。因此,在说服我们的财务总监花费我们来之不易的自筹资金之前,我想尽可能多地免费获得。我也是一名具有数据和计算机科学背景的分析师,所以无论从哪个角度来说,我都是个极客。
戴上我的谷歌 SEO 分析师帽子,我试图做的是寻找大量免费数据来源,并将其转化为有见地的东西。为什么?因为将客户的建议建立在猜测之上是没有价值的。将质量数据与良好的分析相结合,并帮助我们的客户更好地了解他们关注的重点是更好的。
在本文中,我将告诉您如何开始使用一些免费资源,并说明如何整合独特的分析,如果您是作家,如何为您的博客文章提供有用的见解,如果您是谷歌 SEO,您的代理机构,或您的网站,如果您是自己进行谷歌搜索引擎优化的客户或所有者。
我将要使用的场景是我想分析一些 google SEO 属性(例如反向链接、页面权限等)并查看它们对 Google 排名的影响。我想回答诸如“反向链接对进入 SERP 的第 1 页真的很重要吗?”之类的问题。和“我真正需要什么样的页面权威分数才能进入前 10 个结果?” 为此,我需要将来自多个 Google 搜索的数据与每个具有我想要衡量的 google SEO 属性的结果的数据相结合。
让我们开始并研究如何结合以下任务来实现这一点,这些任务都可以免费设置:
- 使用 Google 自定义搜索引擎查询
- 使用免费的 Moz API 帐户
- 使用 PHP 和 MySQL 收集数据
- 使用 SQL 和 R 分析数据
使用 Google 自定义搜索引擎查询
我们首先需要查询谷歌并存储一些结果。为了遵守 Google 的服务条款,我们不会直接抓取 Google.com,而是使用 Google 的自定义搜索功能。Google 的自定义搜索主要是为了让网站所有者在他们的网站上提供类似 Google 的搜索小部件。但是,还有一个基于 REST 的免费 Google 搜索 API,可让您查询 Google 并以流行的 JSON 格式检索结果。有配额限制,但可以配置和扩展这些限制,以提供一个很好的数据样本来使用。
当正确配置为搜索整个网络时,您可以将查询发送到您的自定义搜索引擎,在我们的例子中使用 PHP,并将它们视为 Google 响应,尽管有一些警告。使用自定义搜索引擎的主要限制是:(i) 它不使用某些 Google 网页搜索功能,例如个性化结果;以及;(ii) 如果您包含十个以上的网站,它可能包含来自 Google 索引的结果子集。
尽管有这些限制,但仍有许多搜索选项可以传递给自定义搜索引擎,以代理您可能期望 Google.com 返回的内容。在我们的场景中,我们在调用时传递了以下内容:
https://www.googleapis.com/customsearch/v1?key=<google_api_id>&userIp=
<ip_address>&cx<custom_search_engine_id>&q=iPhone+X&cr=countryUS&start=
1</custom_search_engine_id></ip_address></google_api_id>
在哪里:
- https://www.googleapis.com/customsearch/v1 – 是 Google 自定义搜索 API 的 URL
- key=<GOOGLE_API_ID> – 您的 Google Developer API 密钥
- userIp=<IP_ADDRESS> – 进行调用的本地机器的 IP 地址
- cx=<CUSTOM_SEARCH_ENGINE_ID> – 您的 Google 自定义搜索引擎 ID
- q=iPhone+X – Google 查询字符串(’+’ 替换 ‘ ‘)
- cr=countryUS – 国家限制(来自 Goolge 的国家集合名称列表)
- start=1 – 要返回的第一个结果的索引 – 例如 SERP 第 1 页。连续调用将增加此索引以获取第 2-5 页。
Google 曾表示 Google 自定义搜索引擎与 Google .com 不同,但在我有限的产品测试比较两者之间的结果时,我对相似之处感到鼓舞,因此继续进行分析。也就是说,请记住,以下数据和结果来自 Google 自定义搜索(使用“整个网络”查询),而不是 Google.com。
使用免费的 Moz API 帐户
Moz 提供了一个应用程序编程接口 (API)。要使用它,您需要注册一个 Mozscape API 密钥,该密钥是免费的,但每月限制为 2,500 行,每 10 秒查询一次。当前的付费计划为您提供更高的配额,起价为 250 美元/月。拥有免费帐户和 API 密钥后,您可以查询 Links API 并分析以下指标:
Moz 数据字段Moz API 代码说明
| ueid | 32 | 指向 URL 的外部股权链接的数量 |
| uid | 2048 | 指向 URL 的链接数(外部、公平或非公平) |
| 嗯嗯** | 16384 | URL 的 MozRank,作为标准化的 10 分得分 |
| 嗯** | 16384 | URL 的 MozRank,作为原始分数 |
| fmrp** | 32768 | URL 子域的 MozRank,作为标准化的 10 分得分 |
| fmrr** | 32768 | URL 子域的 MozRank,作为原始分数 |
| 我们 | 536870912 | 为此 URL 记录的 HTTP 状态代码(如果有) |
| 乌帕 | 34359738368 | 标准化的 100 分分数,表示页面在搜索引擎结果中排名良好的可能性 |
| 掌上电脑 | 68719476736 | 一个标准化的 100 分分数,表示一个域在搜索引擎结果中排名良好的可能性 |
注意:由于捕获了此分析,Moz 记录了他们已弃用这些字段。但是,在对此进行测试时(2019 年 6 月 15 日),这些字段仍然存在。
Moz API 代码在调用 Links API 之前添加在一起,如下所示:
www.apple.com%2F?Cols=103616137253&AccessID=MOZ_ACCESS_ID&
Expires=1560586149&Signature=<MOZ_SECRET_KEY>
在哪里:
- http://lsapi.google seomoz.com/linkscape/url-metrics/” class=”redactor-autoparser-object”>http://lsapi.google seomoz.com/linksc… – 是 Moz 的 URL API
- http%3A%2F%2Fwww.apple.com%2F – 我们想要获取数据的编码 URL
- Cols=103616137253 – 上表中 Moz API 代码的总和
- AccessID=MOZ_ACCESS_ID – Moz 访问 ID 的编码版本(在您的 API 帐户中找到)
- Expires=1560586149 – 查询超时 – 设置为未来几分钟
- Signature=<MOZ_SECRET_KEY> – Moz 访问 ID 的编码版本(在您的 API 帐户中找到)
Moz 将返回类似于以下 JSON 的内容:
数组
(
[ut] => 苹果
[uu] => <a href=”http://www.apple.com/” class=”redactor-autoparser-object”>www.apple.com/</a>
[ ueid] => 13078035
[uid] => 14632963
[uu] => www.apple.com/
[ueid] => 13078035
[uid] => 14632963
[umrp] => 9
[umrr] => 0.8999999762
[fmrp] = > 2.602215052
[fmrr] => 0.2602215111
[us] => 200
[upa] => 90
[pda] => 100
)
有关使用 PHP、Perl、Python、Ruby 和 Javascript 查询 Moz 的一个很好的起点,请参阅 Github 上的这个存储库。我选择使用 PHP。
使用 PHP 和 MySQL 收集数据
现在我们有了一个谷歌自定义搜索引擎和我们的 Moz API,我们几乎准备好捕获数据了。Google 和 Moz 通过 JSON 格式响应请求,因此可以被许多流行的编程语言查询。除了我选择的语言 PHP 之外,我还将 Google 和 Moz 的结果写入数据库并为此选择了 MySQL Community Edition。也可以使用其他数据库,例如 Postgres、Oracle、Microsoft SQL Server 等。这样做可以使用 SQL(结构化查询语言)以及其他语言(如 R,我将介绍这些语言)进行数据持久性和临时分析之后)。在创建数据库表来保存 Google 搜索结果(包含排名、URL 等字段)和保存 Moz 数据字段(ueid、upa、uda 等)的表之后,我们就可以设计我们的数据收集计划了。
Google 为自定义搜索引擎提供了丰厚的配额(使用相同的 Google 开发者控制台密钥,每天最多 1 亿次查询),但 Moz 免费 API 限制为 2,500 个。尽管对于 Moz,付费选项每月提供 120k 到 4000 万行,具体取决于计划,成本范围为每月 250 至 10,000 美元。因此,当我只是在探索免费选项时,我将代码设计为在 2 页 SERP(每页 10 个结果)上收集 125 个 Google 查询,从而使我能够保持在 Moz 2,500 行配额内。至于在 Google 上触发哪些搜索,有很多资源可供使用。我选择使用 Mondovo,因为它们按类别提供了大量列表,每个列表最多 500 个单词,这对于实验来说是足够的。
除了我自己的数据库 I/O 和 HTTP 代码之外,我还加入了一些 PHP 帮助程序类。
总之,使用的主要 PHP 构建块和源代码是:
- Google 自定义搜索引擎 – Ash Kiswany 使用 Jacob Fogg 的 PHP 界面进行 Google 自定义搜索写了一篇出色的文章;
- Mozscape API——如前所述,这个用于在 Github 上访问 Moz 的 PHP 实现是一个很好的起点;
- 网站爬虫和 HTTP——在 Purple Toolz,我们有自己的爬虫,叫做 PurpleToolzBot,它使用 Curl for HTTP 和这个 Simple HTML DOM Parser;
- 数据库 I/O——PHP 对 MySQL 有很好的支持,我将这些教程封装到了类中。
需要注意的一个因素是 Moz API 调用之间的 10 秒间隔。这是为了防止 Moz 被免费的 API 用户超载。为了在软件中处理这个问题,我编写了一个“查询限制器”,它在一个时间范围内的连续调用之间阻止对 Moz API 的访问。然而,虽然工作完美,但这意味着连续调用 Moz 2,500 次只需要不到 7 个小时即可完成。
使用 SQL 和 R 分析数据
收集到的数据。现在乐趣开始了!
是时候看看我们有什么了。这有时被称为数据争吵。我使用名为 R 的免费统计编程语言以及名为 R Studio 的开发环境(编辑器)。还有其他语言,如 Stata 和更多的图形数据科学工具,如 Tableau,但这些成本和 Purple Toolz 的财务总监不是一个可以跨越的人!
我使用 R 已经很多年了,因为它是开源的,并且它有许多第三方库,这使得它非常通用并且适合这种工作。
让我们卷起袖子。
我现在有几个数据库表,其中包含我在 2 个 SERPS 页面上的 125 个搜索词查询的结果(即每个搜索词有 20 个排名 URL)。两个数据库表保存 Google 结果,另一个表保存 Moz 数据结果。要访问这些,我们需要做一个数据库 INNER JOIN,我们可以通过将 RMySQL 包与 R 一起使用来轻松完成它。这是通过在 R 的控制台中键入“install.packages(‘RMySQL’)”并包括“ library(RMySQL)”在我们的 R 脚本的顶部。
然后,我们可以执行以下操作来连接数据并将数据放入名为“theResults”的 R 数据框变量中。
library(RMySQL)
# INNER JOIN 两个表
theQuery <- ”
SELECT A.*, B.*, C.*
FROM
(
SELECT
cseq_search_id
FROM cse_query
) A — 自定义搜索查询
INNER JOIN
(
SELECT
cser_cseq_id,
cser_rank,
cser_url
FROM cse_results
) B — 自定义搜索结果
ON A.cseq_search_id = B.cser_cseq_id
INNER JOIN
(
SELECT *
FROM moz
) C — Moz 数据字段
ON B.cser_url = C.moz_url
;
”
# [1] 连接到数据库
# 替换 USER_NAME使用您的数据库用户名
# 将 PASSWORD 替换为您的数据库密码
# 将 MY_DB 替换为您的数据库名称
theConn <- dbConnect(dbDriver(“MySQL”), user = “USER_NAME”, password = “PASSWORD”, dbname = “MY_DB”)
# [2] 查询数据库并保存结果
theResults < – dbGetQuery(theConn, theQuery)
# [3] 断开与数据库的连接
dbDisconnect(theConn)
注意:我有两个表来保存 Google 自定义搜索引擎数据。一个保存 Google 查询的数据 (cse_query),一个保存结果 (cse_results)。
我们现在可以使用 R 的全部统计函数来开始争论。
让我们从一些摘要开始,以了解数据。对于每个字段,我所经历的过程基本相同,所以让我们说明并使用 Moz 的“UEID”字段(指向 URL 的外部股权链接的数量)。通过在 RI 中输入以下内容,可以得到:
> 摘要(theResults$moz_ueid)
最小。第一曲。中位数平均第三曲。最大限度。
0 1 20 14709 182 2755274
> 分位数(结果$moz_ueid,probs = c(1, 5, 10, 25, 50, 75, 80, 90, 95, 99, 100)/100)
1% 5% 10% 25% 50% 75% 80% 90% 95% 99% 100%
0.0 0.0 0.0 1.0 20.0 182.0 337.2 1715.2 7873.4 412283.4 2755274.0
看看这个,您可以看到数据因中位数与均值的关系而出现偏差(很多),而中位数与均值的关系被上四分位数范围内的值(超过 75% 的观测值)拉动。但是,我们可以将其绘制为 R 中的箱须图,其中每个 X 值是按 Google 自定义搜索位置 1-20 排名的 UEID 分布。
请注意,我们在 y 轴上使用了对数刻度,以便我们可以显示全范围的值,因为它们变化很大!
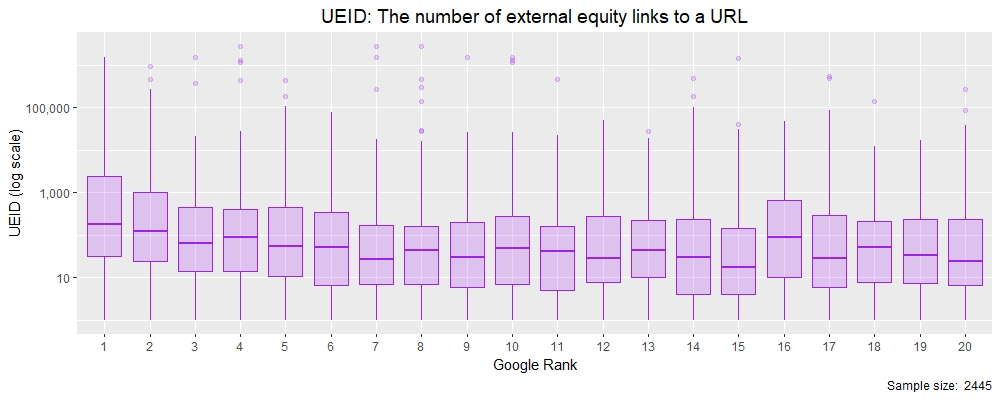 Moz 的 UEID R 中的盒须图(按 Google 排名)(注:对数刻度)
Moz 的 UEID R 中的盒须图(按 Google 排名)(注:对数刻度)
箱线图和须线图很棒,因为它们显示了很多信息(请参阅 R 中的 geom_boxplot 函数)。紫色方框区域代表四分位间距 (IQR),它是 25% 到 75% 观察值之间的值。每个“盒子”中的水平线代表中间值(订购时位于中间的那个),而从盒子延伸的线(称为“晶须”)代表 1.5x IQR。胡须外的点称为“异常值”,显示每个等级的观察集的范围。尽管有对数规模,但我们可以看到从排名第 10 位到排名第 1 位的中值明显上升,这表明股权链接的数量可能是 Google 排名因素。让我们用密度图进一步探讨这个问题。
密度图很像分布(直方图),但显示的是平滑线而不是数据条。与直方图非常相似,密度图的峰值显示了数据值的集中位置,并且可以在比较两个分布时提供帮助。在下面的密度图中,我将数据分为两类:(i)出现在排名 1-10 的 SERP 第 1 页上的结果是粉红色的;(ii) SERP 第 2 页上出现的结果为蓝色。我还绘制了两个分布的中位数,以帮助说明第 1 页和第 2 页之间结果的差异。
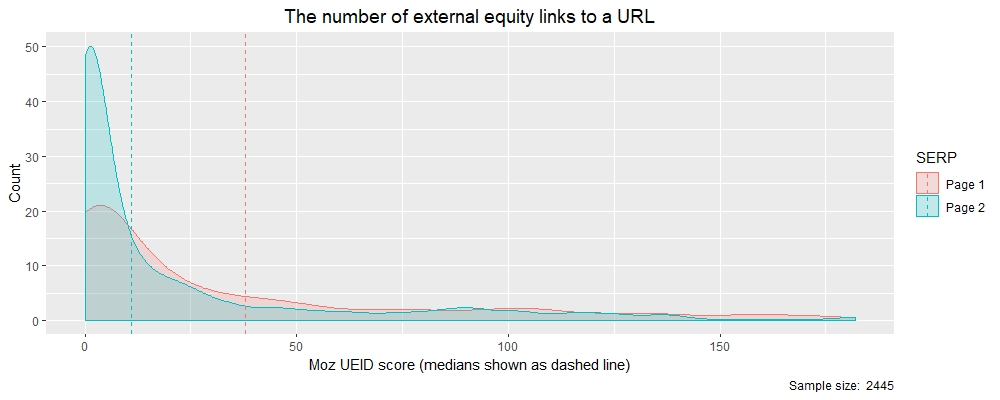
从这两个密度图推断,第 1 页 SERP 结果比第 2 页结果具有更多的外部股权反向链接 (UEID)。您还可以在下面看到这两个类别的中值,清楚地显示第 1 页 (38) 的值如何远大于第 2 页 (11)。所以我们现在有一些数字可以作为我们反向链接的谷歌搜索引擎优化策略的基础。
# 根据结果 (cser_rank) 所在的 SERP 页面在 R 中创建一个因子
> theResults$rankBin <- paste(“Page”, ceiling(theResults$cser_rank / 10))
> theResults$rankBin <- factor(theResults$rankBin ) # 现在通过调用 ‘tapply’ > tapply(theResults$moz_ueid, theResults$rankBin, median) Page 1 Page 2 38 11
按 SERP 页面报告中位数
由此,我们可以推断出股权反向链接 (UEID) 很重要,如果我根据这些数据为客户提供建议,我会说他们应该寻求超过 38 个基于股权的反向链接,以帮助他们进入 SERP 的第 1 页。当然,这是一个有限的样本,需要更多的研究、更大的样本和其他排名因素,但你明白了。
现在让我们研究另一个比 UEID 范围更小的指标,并查看 Moz 的 UPA 度量,即页面在搜索引擎结果中排名良好的可能性。
> 摘要(theResults$moz_upa)
最小。第一曲。中位数平均第三曲。最大限度。
1.00 33.00 41.00 41.22 50.00 81.00
> 分位数(结果$moz_upa, probs = c(1, 5, 10, 25, 50, 75, 80, 90, 95, 99, 100)/100)
1% 5% 10% 25% 50% 75% 80% 90% 95% 99% 100%
12 20 25 33 41 50 53 58 62 75 81
UPA 是赋予 URL 的数字,范围在 0 到 100 之间。与之前的 UEID 无界变量相比,该数据的表现更好,其均值和中位数接近,从而形成更“正态”的分布,正如我们通过在 R 中绘制直方图在下面看到的那样。
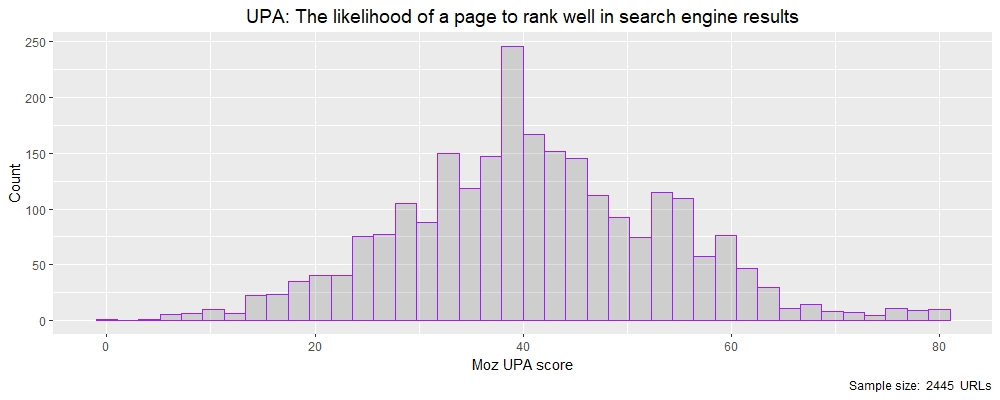 Moz 的 UPA 分数直方图
Moz 的 UPA 分数直方图
我们将执行与之前相同的第 1 页:第 2 页拆分和密度图,并在将 UPA 数据分为两组时查看 UPA 分数分布。
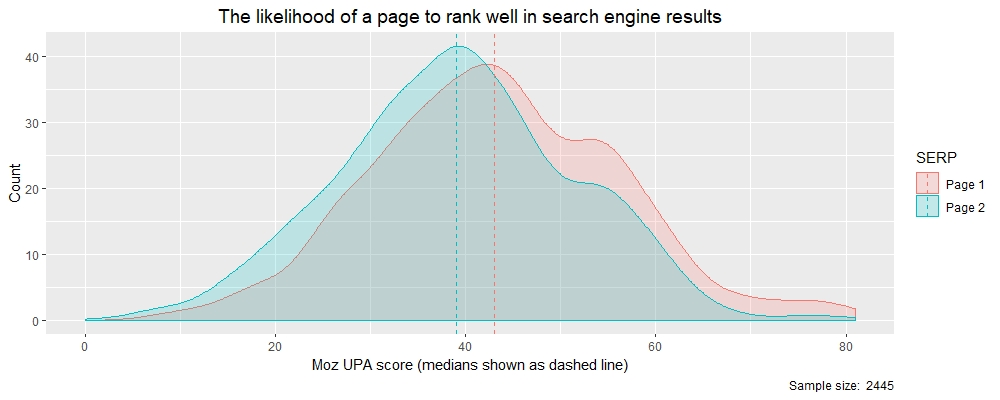
# 通过调用 ‘tapply’
> tapply(theResults$moz_upa, theResults$rankBin, median)
Page 1 Page 2
43 39报告 SERP 页面的中位数
总之,来自两个 Moz API 变量的两个非常不同的分布。但两者都显示出 SERP 页面之间的分数差异,并为您提供有形的价值(中位数)以供您使用并最终为客户提供建议或申请您自己的谷歌 SEO。
当然,这只是一个小样本,不应该从字面上理解。但是借助 Google 和 Moz 提供的免费资源,您现在可以了解如何开始开发自己的分析能力,以基于您的假设而不是接受规范。谷歌搜索引擎优化排名因素一直在变化,拥有自己的分析工具来进行自己的测试和实验将帮助你获得可信度,甚至可能对前所未有的事物有独特的见解。
谷歌为您提供了一个健康的免费配额来获取搜索结果。如果您需要超过 2,500 行/月的 Moz 免费提供,您可以购买许多付费计划。MySQL 是免费下载的,R 也是一个免费的统计分析包(等等)。
去探索吧!



