
While google SEOs have been doubling-down on content and quality signals for their websites, Google was building the foundation of a new reality for crawling — indexing and ranking. Though many believe deep in their hearts that “Content is King,” the reality is that Mobile-First Indexing enables a new kind of search result. This search result focuses on surfacing and re-publishing content in ways that feed Google’s cross-device monetization opportunities better than simple websites ever could.
For two years, Google honed and changed their messaging about Mobile-First Indexing, mostly de-emphasizing the risk that good, well-optimized, Responsive-Design sites would face. Instead, the search engine giant focused more on the use of the Smartphone bot for indexing, which led to an emphasis on the importance of matching google SEO-relevant site assets between desktop and mobile versions (or renderings) of a page. Things got a bit tricky when Google had to explain that the Mobile-First Indexing process would not necessarily be bad for desktop-oriented content, but all of Google’s shifting and positioning eventually validated my long-stated belief: That Mobile-First Indexing is not really about mobile phones, per se, but mobile content.
I would like to propose an alternative to the predominant view, a speculative theory, about what has been going on with Google in the past two years, and it is the thesis of my 2019 MozCon talk — something we are calling Fraggles and Fraggle-based Indexing.
I’ll go through Fraggles and Fraggle-based indexing, and how this new method of indexing has made web content more ‘liftable’ for Google. I’ll also outline how Fraggles impact the Search Results Pages (SERPs), and why it fits with Google’s promotion of Progressive Web Apps. Next, I will provide information about how astute google SEO’s can adapt their understanding of google SEO and leverage Fraggles and Fraggle-Based Indexing to meet the needs of their clients and companies. Finally, I’ll go over the implications that this new method of indexing will have on Google’s monetization and technology strategy as a whole.
Ready? Let’s dive in.
Fraggles & Fraggle-based indexing
The SERP has changed in many ways. These changes can be thought of and discussed separately, but I believe that they are all part of a larger shift at Google. This shift includes “Entity-First Indexing” of crawled information around the existing structure of Google’s Knowledge Graph, and the concept of “Portable-prioritized Organization of Information,” which favors information that is easy to lift and re-present in Google’s properties — Google describes these two things together as “Mobile-First Indexing.”
As google SEOs, we need to remember that the web is getting bigger and bigger, which means that it’s getting harder to crawl. Users now expect Google to index and surface content instantly. But while webmasters and google SEOs were building out more and more content in flat, crawlable HTML pages, the best parts of the web were moving towards more dynamic websites and web-apps. These new assets were driven by databases of information on a server, populating their information into websites with JavaScript, XML or C++, rather than flat, easily crawlable HTML.
For many years, this was a major problem for Google, and thus, it was a problem for google SEOs and webmasters. Ultimately though, it was the more complex code that forced Google to shift to this more advanced, entity-based system of indexing — something we at MobileMoxie call Fraggles and Fraggle-Based Indexing, and the credit goes to JavaScript’s “Fragments.”
Fraggles represent individual parts (fragments) of a page for which Google overlayed a “handle” or “jump-link” (aka named-anchor, bookmark, etc.) so that a click on the result takes the users directly to the part of the page where the relevant fragment of text is located. These Fraggles are then organized around the relevant nodes on the Knowledge Graph, so that the mapping of the relationships between different topics can be vetted, built-out, and maintained over time, but also so that the structure can be used and reused, internationally — even if different content is ranking.
More than one Fraggle can rank for a page, and the format can vary from a text-link with a “Jump to” label, an unlabeled text link, a site-link carousel, a site-link carousel with pictures, or occasionally horizontal or vertical expansion boxes for the different items on a page.
The most notable thing about Fraggles is the automatic scrolling behavior from the SERP. While Fraggles are often linked to content that has an HTML or JavaScript jump-links, sometimes, the jump-links appear to be added by Google without being present in the code at all. This behavior is also prominently featured in AMP Featured Snippets, for which Google has the same scrolling behavior, but also includes Google’s colored highlighting — which is superimposed on the page — to show the part of the page that was displayed in the Featured Snippet, which allows the searcher to see it in context. I write about this more in the article: What the Heck are Fraggles.
How Fraggles & Fraggle-based indexing works with JavaScript
Google’s desire to index Native Apps and Web Apps, including single-page apps, has necessitated Google’s switch to indexing based on Fragments and Fraggles, rather than pages. In JavaScript, as well as in Native Apps, a “Fragment” is a piece of content or information that is not necessarily a full page.
The easiest way for an google SEO to think about a Fragment is within the example of an AJAX expansion box: The piece of text or information that is fetched from the server to populate the AJAX expander when clicked could be described as a Fragment. Alternatively, if it is indexed for Mobile-First Indexing, it is a Fraggle.
It is no coincidence that Google announced the launch of Deferred JavaScript Rendering at roughly the same time as the public roll-out of Mobile-First Indexing without drawing-out the connection, but here it is: When Google can index fragments of information from web pages, web apps and native apps, all organized around the Knowledge Graph, the data itself becomes “portable” or “mobile-first.”
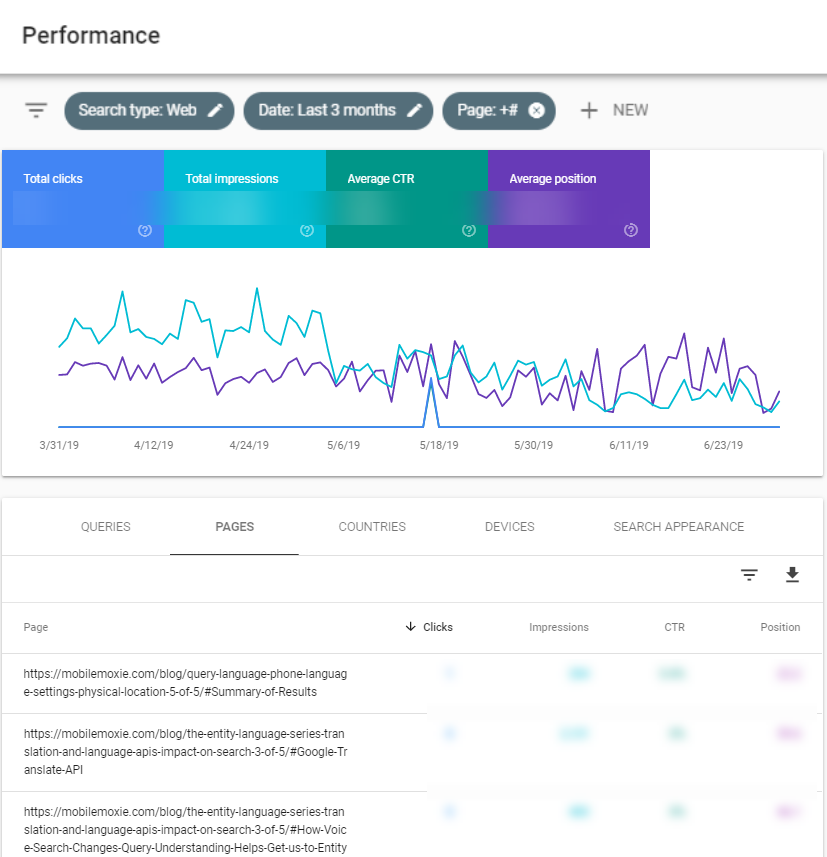
We have also recently discovered that Google has begun to index URLs with a # jump-link, after years of not doing so, and is reporting on them separately from the primary URL in Search Console. As you can see below from our data, they aren’t getting a lot of clicks, but they are getting impressions. This is likely because of the low average position.
Before Fraggles and Fraggle-Based Indexing, indexing # URLs would have just resulted in a massive duplicate content problem and extra work indexing for Google. Now that Fraggle-based Indexing is in-place, it makes sense to index and report on # URLs in Search Console — especially for breaking up long, drawn-out JavaScript experiences like PWA’s and Single-Page-Apps that don’t have separate URLs, databases, or in the long-run, possibly even for indexing native apps without Deep Links.
Why index fragments & Fraggles?
If you’re used to thinking of rankings with the smallest increment being a URL, this idea can be hard to wrap your brain around. To help, consider this thought experiment: How useful would it be for Google to rank a page that gave detailed information about all different kinds of fruits and vegetables? It would be easy for a query like “fruits and vegetables,” that’s for sure. But if the query is changed to “lettuce” or “types of lettuce,” then the page would struggle to rank, even if it had the best, most authoritative information.
This is because the “lettuce” keywords would be diluted by all the other fruit and vegetable content. It would be more useful for Google to rank the part of the page that is about lettuce for queries related to lettuce, and the part of the page about radishes well for queries about radishes. But since users don’t want to scroll through the entire page of fruits and vegetables to find the information about the particular vegetable they searched for, Google prioritizes pages with keyword focus and density, as they relate to the query. Google will rarely rank long pages that covered multiple topics, even if they were more authoritative.
With featured snippets, AMP featured snippets, and Fraggles, it’s clear that Google can already find the important parts of a page that answers a specific question — they’ve actually been able to do this for a while. So, if Google can organize and index content like that, what would the benefit be in maintaining an index that was based only on per-pages statistics and ranking? Why would Google want to rank entire pages when they could rank just the best parts of pages that are most related to the query?
To address these concerns, historically, google SEO’s have worked to break individual topics out into separate pages, with one page focused on each topic or keyword cluster. So, with our vegetable example, this would ensure that the lettuce page could rank for lettuce queries and the radish page could rank for radish queries. With each website creating a new page for every possible topic that they would like to rank for, there’s lot of redundant and repetitive work for webmasters. It also likely adds a lot of low-quality, unnecessary pages to the index. Realistically, how many individual pages on lettuce does the internet really need, and how would Google determine which one is the best? The fact is, Google wanted to shift to an algorithm that focused less on links and more on topical authority to surface only the best content — and Google circumvents this with the scrolling feature in Fraggles.
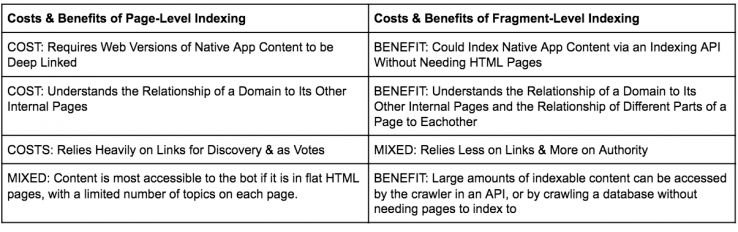
Even though the effort to switch to Fraggle-based indexing, and organize the information around the Knowledge Graph, was massive, the long-term benefits of the switch far out-pace the costs to Google because they make Google’s system for flexible, monetizable and sustainable, especially as the amount of information and the number of connected devices expands exponentially. It also helps Google identify, serve and monetize new cross-device search opportunities, as they continue to expand. This includes search results on TV’s, connected screens, and spoken results from connected speakers. A few relevant costs and benefits are outlined below for you to contemplate, keeping Google’s long-term perspective in mind:
Why Fraggles and Fraggle-based indexing are important for PWAs
What also makes the shift to Fraggle-based Indexing relevant to google SEOs is how it fits in with Google’s championing of Progressive Web Apps or AMP Progressive Web Apps, (aka PWAs and PWA-AMP websites/web apps). These types of sites have become the core focus of Google’s Chrome Developer summits and other smaller Google conferences.
From the perspective of traditional crawling and indexing, Google’s focus on PWAs is confusing. PWAs often feature heavy JavaScript and are still frequently built as Single-Page Apps (SPA’s), with only one or only a few URLs. Both of these ideas would make PWAs especially difficult and resource-intensive for Google to index in a traditional way — so, why would Google be so enthusiastic about PWAs?
The answer is because PWA’s require ServiceWorkers, which uses Fraggles and Fraggle-based indexing to take the burden off crawling and indexing of complex web content.
In case you need a quick refresher: ServiceWorker is a JavaScript file — it instructs a device (mobile or computer) to create a local cache of content to be used just for the operation of the PWA. It is meant to make the loading of content much faster (because the content is stored locally) instead of just left on a server or CDN somewhere on the internet and it does so by saving copies of text and images associated with certain screens in the PWA. Once a user accesses content in a PWA, the content doesn’t need to be fetched again from the server. It’s a bit like browser caching, but faster — the ServiceWorker stores the information about when content expires, rather than storing it on the web. This is what makes PWAs seem to work offline, but it is also why content that has not been visited yet is not stored in the ServiceWorker.
ServiceWorkers and google SEO
Most google SEOs who understand PWAs understand that a ServiceWorker is for caching and load time, but they may not understand that it is likely also for indexing. If you think about it, ServiceWorkers mostly store the text and images of a site, which is exactly what the crawler wants. A crawler that uses Deferred JavaScript Rendering could go through a PWA and simulate clicking on all the links and store static content using the framework set forth in the ServiceWorker. And it could do this without always having to crawl all the JavaScript on the site, as long as it understood how the site was organized, and that organization stayed consistent.
Google would also know exactly how often to re-crawl, and therefore could only crawl certain items when they were set to expire in the ServiceWorker cache. This saves Google a lot of time and effort, allowing them to get through or possibly skip complex code and JavaScript.
For a PWA to be indexed, Google requires webmasters to ‘register their app in Firebase,’ but they used to require webmasters to “register their ServiceWorker.” Firebase is the Google platform that allows webmasters to set up and manage indexing and deep linking for their native apps, chat-bots and, now, PWA’s.
Direct communication with a PWA specialist at Google a few years ago revealed that Google didn’t crawl the ServiceWorker itself, but crawled the API to the ServiceWorker. It’s likely that when webmasters register their ServiceWorker with Google, Google is actually creating an API to the ServiceWorker, so that the content can be quickly and easily indexed and cached on Google’s servers. Since Google has already launched an Indexing API and appears to now favor API’s over traditional crawling, we believe Google will begin pushing the use of ServiceWorkers to improve page speed, since they can be used on non-PWA sites, but this will actually be to help ease the burden on Google to crawl and index the content manually.
Flat HTML may still be the fastest way to get web information crawled and indexed with Google. For now, JavaScript still has to be deferred for rendering, but it is important to recognize that this could change and crawling and indexing is not the only way to get your information to Google. Google’s Indexing API, which was launched for indexing time-sensitive information like job postings and live-streaming video, will likely be expanded to include different types of content.
It’s important to remember that this is how AMP, Schema, and many other types of powerful google SEO functionalities have started with a limited launch; beyond that, some great google SEO’s have already tested submitting other types of content in the API and seen success. Submitting to APIs skips Google’s process of blindly crawling the web for new content and allows webmasters to feed the information to them directly.
It is possible that the new Indexing API follows a similar structure or process to PWA indexing. Submitted URLs can already get some kinds of content indexed or removed from Google’s index, usually in about an hour, and while it is only currently officially available for the two kinds of content, we expect it to be expanded broadly.
How will this impact google SEO strategy?
Of course, every google SEO wants to know how to leverage this speculative theory — how can we make the changes in Google to our benefit?
The first thing to do is take a good, long, honest look at a mobile search result. Position #1 in the organic rankings is just not what it used to be. There’s a ton of engaging content that is often pushing it down, but not counting as an organic ranking position in Search Console. This means that you may be maintaining all your organic rankings while also losing a massive amount of traffic to SERP features like Knowledge Graph results, Featured Snippets, Google My Business, maps, apps, Found on the Web, and other similar items that rank outside of the normal organic results.
These results, as well as Pay-per-Click results (PPC), are more impactful on mobile because they are stacked above organic rankings. Rather than being off to the side, as they might be in a desktop view of the search, they push organic rankings further down the results page. There has been some great reporting recently about the statistical and large-scale impact of changes to the SERP and how these changes have resulted in changes to user-behavior in search, especially from Dr. Pete Meyers, Rand Fishkin, and JumpTap.
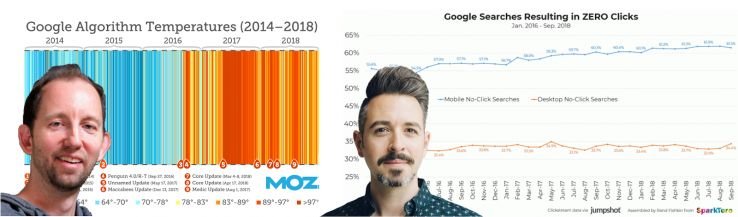
Dr. Pete has focused on the increasing number of changes to the Google Algorithm recorded in his MozCast, which heated up at the end of 2016 when Google started working on Mobile-First Indexing, and again after it launched the Medic update in 2018.
Rand, on the other hand, focused on how the new types of rankings are pushing traditional organic results down, resulting in less traffic to websites, especially on mobile. All this great data from these two really set the stage for a fundamental shift in google SEO strategy as it relates to Mobile-First Indexing.
研究表明,谷歌重新组织了其索引以适应不同的信息呈现方式——特别是如果他们能够围绕知识图谱中的实体概念索引该信息。基于 Fraggle 的索引使 Google 抓取的所有信息更加便携,因为它智能地嵌套在相关的知识图节点中,可以以各种不同的方式呈现。由于基于 Fraggle 的索引更多地关注有意义的数据组织,而不是页面和 URL,因此结果是 SERP 中信息的更“窗口化”呈现。谷歌 SEO 需要了解搜索结果现在基于实体和用例(想想微时刻),而不是页面和域。
谷歌的知识图谱
要真正了解这种新的索引方法将如何影响您的 google SEO 策略,您首先必须了解 Google 的知识图谱是如何工作的。
由于它是一个实际的“图”,所有知识图条目(节点)都包括垂直和横向关系。例如,“面包”的条目可以包括与奶酪、黄油和蛋糕等相关主题的横向关系,但也可以包括垂直关系,例如“面包中的标准成分”或“面包类型”。
横向关系可以看作是知识图谱上的相关节点,暗示“Related Topics”,而纵向关系则指向主题的扩大或缩小;这暗示了主题中最有可能的过滤器。就面包而言,垂直向上的关系是“烘焙”等主题,向下的主题包括“面粉”和其他用于制作面包的配料,或“酸面团”和其他特定类型的面包。
谷歌 SEO 应该注意,知识图谱条目现在可以包含越来越多的过滤器和选项卡,这些过滤器和选项卡可以缩小主题信息的范围,从而有利于不同类型的搜索者意图。这包括帮助搜索者查找视频、书籍、图像、引用、位置等内容,但在过滤器的情况下,它可能是特定主题且不可预测的(通过主动机器学习提供信息)。这是谷歌基于 Fraggle 索引的目标的关键:能够基于知识图条目或节点组织网络信息,否则在谷歌 SEO 圈子中被称为“实体”。
由于一个实体与另一个实体的关系保持不变,无论一个人说什么或搜索什么语言,知识图谱信息与语言无关,因此很容易同时用于所有语言的聚合和机器学习。因此,使用知识图作为索引的基石是谷歌以多种语言访问和提供信息以供消费和在世界范围内排名的一种更有用和有效的方法。从长远来看,它远远优于以前的索引方法。
SERP 中基于 Fraggle 的索引示例
知识图谱
谷歌大幅增加了知识图条目的数量以及其中的类别和关系。对于谷歌已经拥有大量结构化数据和信息的主题,这种扩展尤为突出。这包括以下主题:
- 电视和电影 — 来自 Google Play
- 食物和食谱——来自食谱模式、食谱 AMP 页面和外部食物和营养数据库
- 科学和医学——来自可信来源(如 WebMD)
- 企业 — 来自 Google 我的企业。
谷歌正在向他们的图表中添加越来越多的节点和关系,现有的条目也正在构建更多的选项卡和轮播,以将单个主题分解为更小、更细化的主题或信息类型。
正如您在下面看到的,知识图的构建也增加了许多查询中的过滤器和向下钻取选项的数量,甚至在知识图之外。这种增长可以在所有谷歌资产中看到,包括谷歌我的商家和购物,我们认为这两者现在都是知识图谱的一部分:
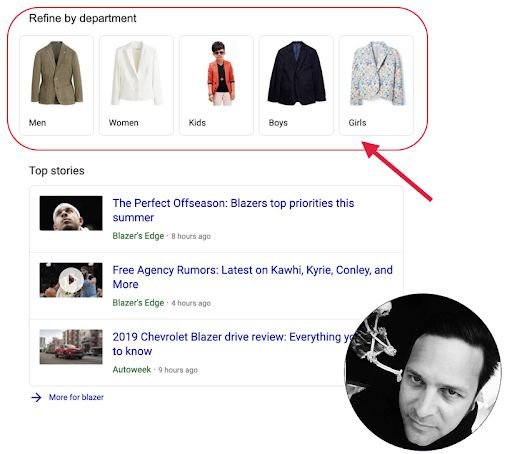 谷歌搜索“开拓者”,顶部带有视觉过滤器,用于面向购物的查询
谷歌搜索“开拓者”,顶部带有视觉过滤器,用于面向购物的查询
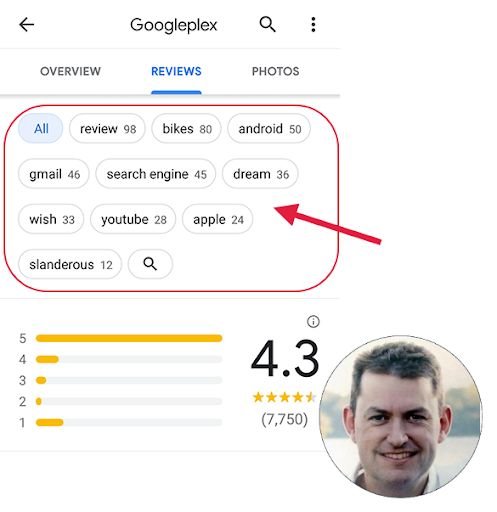 Google 我的业务(业务知识图),带有有关 Googleplex 信息的过滤器
Google 我的业务(业务知识图),带有有关 Googleplex 信息的过滤器
其他类似的例子包括额外的过滤器和谷歌图像中的“相关主题”结果,我们也认为它们代表知识图上的节点:
发现 0 个高级问题▲ 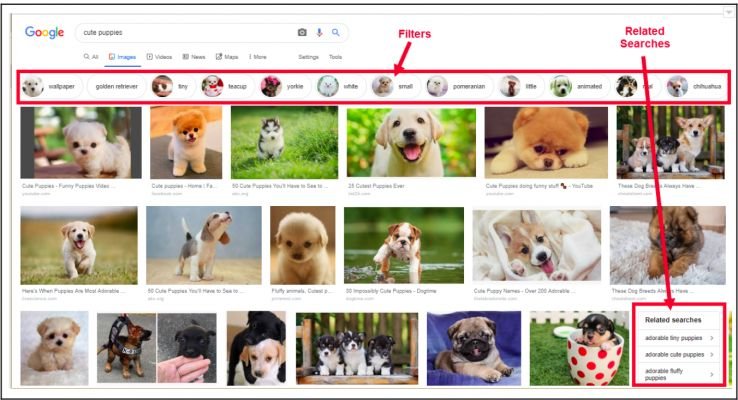 Google Images 增加过滤器和包含相关主题意味着这些也是知识图谱上的节点
Google Images 增加过滤器和包含相关主题意味着这些也是知识图谱上的节点
Knowedge Graph 也以各种不同的方式呈现。有时,在 SERP 的顶部会有一个粘性导航,正如在许多面向媒体的查询中所见,有时它会被分解以在整个 SERP 中显示不同的信息,正如您可能已经在许多面向本地业务的搜索中注意到的那样结果,如下所示。
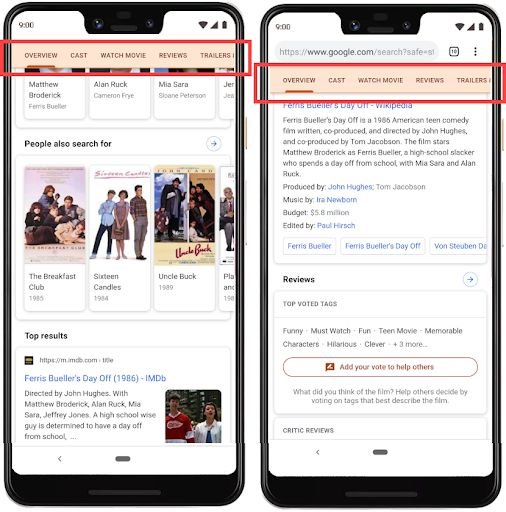 具有粘性顶部导航的媒体知识图(查询“Ferris Bueller’s Day Off”)
具有粘性顶部导航的媒体知识图(查询“Ferris Bueller’s Day Off”)
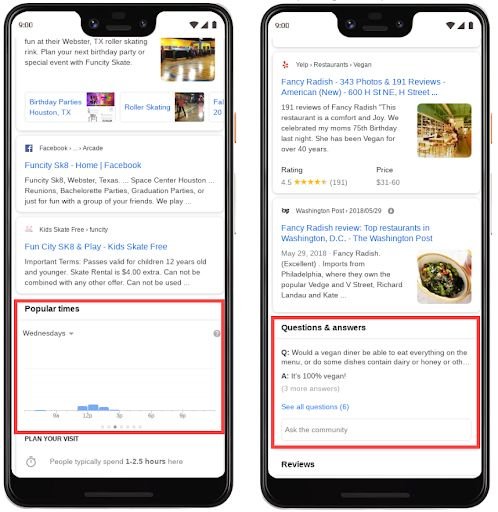 本地业务知识图 (GMB),在整个 SERP 中具有信息拆分
本地业务知识图 (GMB),在整个 SERP 中具有信息拆分
由于基于 Fraggle 的索引的推出本质上是一个主要的知识图谱构建,知识图谱结果也开始包含更多引人入胜的内容,这使得用户点击进入网站的可能性更低。可播放的视频和音频、现场体育比分以及交通信息和电视时间表等特定位置信息等资产都可以直接在搜索结果中访问。不过,故事还有更多。
谷歌也越来越多地通过重新混合他们已经索引的现有信息来创建自己的专有内容,以创建独特的、引人入胜的内容,如动画“AMP 故事”,也鼓励网站管理员自行构建。他们还开始建造一个 AR 动物动物园,可以作为知识图谱结果的一部分显示,同时鼓励开发人员使用他们的 AR 工具包来构建他们自己的 AR 资产,毫无疑问,这些资产最终将被选择性地纳入知识图谱也。
 知识图谱中的 Google AR 动物
知识图谱中的 Google AR 动物
 Google AMP 故事现在称为“图像中的生命”
Google AMP 故事现在称为“图像中的生命”
谷歌 SEO 知识图谱策略
想要利用知识图谱的公司应该抓住一切机会创建自己的资产,比如 AR 模型和 AMP 故事,这样谷歌就没有理由去做了。除此之外,公司应尽可能直接向谷歌提交准确的信息。最简单的方法是通过“Google 我的商家”(GMB)。应添加或上传专线小巴中要求的任何类型的信息。如果 Google Posts 在您的业务类别中可用,您应该定期发布 Posts,并确保它们通过号召性用语链接回您的网站。如果您有与贵公司相关的视频或照片,请将它们上传到 GMB。开始将 GMB 视为社交网络或时事通讯 – 在 Facebook 或 Twitter 上共享的任何资产也可以在 Google Posts 上共享,或者至少上传到 GMB 帐户。
您还应该调查与您的行业相关的当前知识图谱条目,并努力与该行业中公认的公司或实体建立联系。这可能来自实体网站上的链接或引用,但也可能包括被提供行业特定建议和建议的第三方列表链接,例如被列为您所在行业的顶级竞争对手(“丹佛最佳管道工”、“网络上最优惠的鞋子”或“15 大最佳真人秀”)。来自这些帖子的链接也有帮助,但不是必需的——特别是如果您可以让您的公司名称与其他顶级玩家一起出现在足够多的列表中。验证来自权威第三方网站(如维基百科、商业改进局、行业目录、
虽然这只是推测而不是经过验证的谷歌搜索引擎优化策略,但您可能还想通过检查与它相关的行业来确保您的域在谷歌的记录中被正确分类。您可以在 Google 的 MarketFinder 工具中这样做。根据需要进行更新或推荐新类别。然后,查看作为知识图条目的一部分给出的过滤器和关系,并确保您在网站上使用主题和过滤器词作为关键字。
精选片段
精选片段或“答案”于 2014 年首次出现,并且也有相当大的扩展,如下图所示。将精选片段视为没有完整知识图谱结果的流氓事实、想法或概念是有用的,尽管它们实际上可能与知识图谱上的某些现有节点相关联(或者它们可能在审查过程中最终的知识图构建)。
当信息来自谷歌没有高度信任的来源时,精选片段似乎会浮出水面,就像它对维基百科一样,而且它们通常来自第三方网站,这些网站可能有也可能没有金钱利益。主题——让谷歌想要更彻底地审查信息并可能阻止谷歌使用它的东西,如果有一个更小的偏见选项可用的话。
与知识图谱一样,精选片段的结果在过去一年左右的时间里增长非常迅速,并且也开始包括轮播——Rob Bucci 在这里广泛地写了一些内容。我们认为这些轮播代表了谷歌从知识图谱中了解到的潜在相关主题。特色片段现在看起来更像是迷你知识图条目:轮播似乎包括横向和纵向相关的主题,它们的出现和维护似乎是由点击量和后续搜索驱动的。但是,这也可能受到人们还询问和相关搜索数据的聚合参与数据的影响。
精选片段的构建如此激进,以至于有时谷歌提出的答案显然是错误的,如下面的示例图片所示。同样重要的是要了解精选摘要结果可能会因位置而异,并且与语言无关,因此不会翻译以匹配搜索语言或电话语言设置。谷歌也不坚持任何一致性标准,因此一个查询的精选片段可能会以一种方式呈现答案,而针对同一事实的类似查询可能会呈现信息略有不同的精选片段。例如,查询“煮一个鸡蛋要多长时间”可能会得到“5 分钟”的答案,而查询“如何制作一个煮熟的鸡蛋”会得到不同的答案
 带有轮播精选的精选片段
带有轮播精选的精选片段
 错误的片段
错误的片段
下面的数据是由 Moz 收集的,代表了大约 10,000 的平均值,略微偏向“头部”术语。
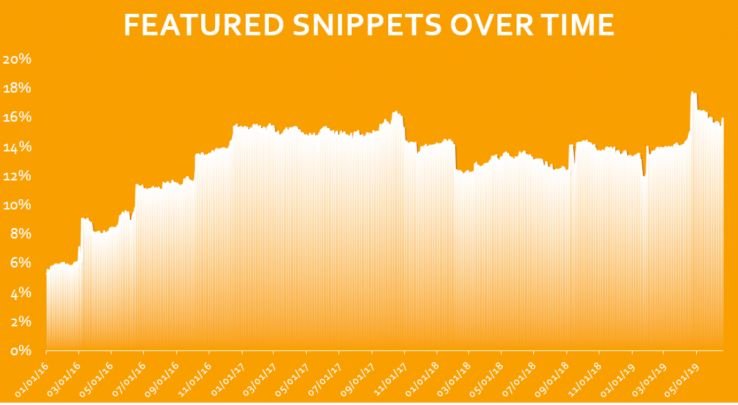 此数据由 Moz 收集并代表大约 10,000 的平均值,略微偏向“头部”术语
此数据由 Moz 收集并代表大约 10,000 的平均值,略微偏向“头部”术语
特色片段的谷歌搜索引擎优化策略
驱动精选片段的所有标准建议都适用于此处。这包括确保您在精选摘要中保持您试图获得排名的信息清晰、直接,并且在推荐的字符数范围内。它还包括使用简单的表格、有序列表和项目符号来使数据更易于使用,以及根据您所在行业的现有精选摘要结果对您的内容进行建模。
这仍然是推测性的,但似乎包含 Speakable Schema 标记的“How To”、“FAQ”和“Q&A”等内容也可能会推动精选片段。这些类型的结果被特别指定为在语音搜索中效果很好的内容。由于谷歌一直坚持只有一个索引,而且谷歌非常专注于改善谷歌智能助理设备的语音结果,任何在谷歌智能助理中可能是好的结果,并且排名很好的,也可能有更强的有机会在精选片段中排名。
人们还询问和相关搜索
最后,不可否认的是,“相关搜索”的出现次数增加以及人们也问 (PAA) 问题的出现,就在大多数知识图谱和精选摘要结果的下方。Earl Tea 屏幕截图显示 PAA 和 Interesting Finds 也是知识图谱的一部分。
下图显示了 PAA 的稳步增长。PAA 结果似乎是 Featured Snippets 的扩展,因为一旦扩展,就会显示问题的答案,并在其下方引用。同样,一些相关搜索结果现在也包含一个看起来像精选摘要的结果,而不是简单地链接到不同的搜索结果。您现在可以在整个 SERP 中找到“相关搜索”,通常作为知识图谱结果的一部分,但有时也在 SERP 中间的轮播中,并且始终在 SERP 的底部——有时带有图像和扩展按钮直接在现有 SERP 中显示相关搜索结果中的精选片段。
具有相关搜索的框现在也包含在图像搜索结果中。有趣的是,谷歌图片中的相关搜索结果在谷歌开始翻译图片标题标签和替代标签的同时开始出现。它与实体优先索引、实体和知识图与语言无关以及相关搜索在某种程度上与知识图相关的概念非常吻合。
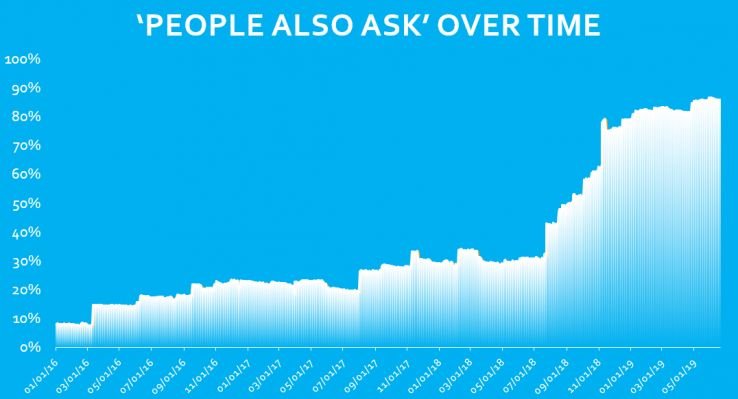
该数据由 Moz 收集,代表大约 10,000 的平均值,略微偏向“头部”术语。
 人们也问
人们也问
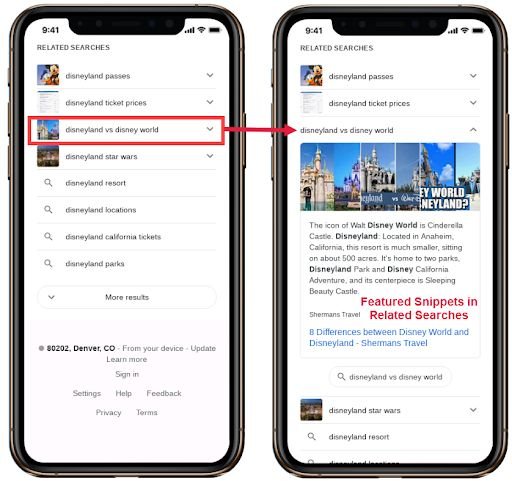 相关搜索
相关搜索
PAA 和相关搜索的谷歌 SEO 策略
由于 PAA 和一些相关搜索现在似乎只包含精选片段,因此为您的网站驱动精选片段结果也是一个强有力的策略。通常,PAA 结果似乎包括同一问题的至少两个版本,用不同的语言重新陈述,然后包括与知识图上的横向和垂直节点更相关的问题。根据相关搜索和 PAA 问题,如果您在网站上包含 Google 认为与该主题相关的信息,则可能有助于使您的网站显得相关且具有权威性。
最后,重要的是要记住你现在没有网站可以在谷歌中排名,谷歌搜索引擎优化也应该将非网站排名视为他们工作的一部分。
如果企业没有网站,或者您只想涵盖所有基础内容,您可以让 Google 直接托管您的内容——在尽可能多的地方。我们已经看到,Google 托管的内容通常似乎在 Google 搜索结果和 Google Discover 中得到优先处理,尤其是与传统自然搜索结果的流量下降相比。谷歌现在非常专注于呈现多媒体内容,因此您之前可能在网站上为其创建新页面的任何内容现在都应该考虑用于视频。
Google 我的商家 (GMB) 非常适合没有网站或希望直接通过 Google 托管网站的公司。YouTube 非常适合视频、电视、视频播客、剪辑、动画和教程。如果你有应用程序、书籍、有声读物、播客、电影、电视节目、课程或音乐或 PWA,你可以将其直接提交到 GooglePlay(GooglePlay 中的大部分视频内容现在是交叉填充的在 YouTube 和 YouTube TV 中,但这不一定适用于其他资产)。该策略还可以包括 Google Books 中的书籍、Google Flights 中的航班、Google 旅馆列表中的酒店以及 Google Explore 中的景点。它还包括拥有有效的 AMP 代码,因为 Google 托管 AMP 内容,如果您的网站是经批准的新闻提供商,则还包括 Google 新闻。
基于 Fraggle 索引的谷歌搜索引擎优化跟踪的变化
谷歌搜索引擎优化的最大问题是缺少有机流量,但目前跟踪有机结果的方法通常不会显示诸如知识图、精选片段、PAA、在网络上找到或其他类型的东西结果出现在查询的顶部或自然结果上方的某个位置。自然搜索结果中的第一名已今非昔比,也不再是低于它的任何东西,因此您不能指望这些排名会带来相同的流量。如果谷歌要提升和代表每个人的内容,流量将永远不会到达网站,谷歌搜索引擎优化将不知道他们的努力是否仍在返回相同的货币价值。这个问题对出版商来说尤其棘手,
要记住的另一件事是结果不同——尤其是在移动设备上,结果因设备而异(通常基于屏幕尺寸),但也可能因手机 IOS 而异。它们还可以根据位置或手机的语言设置发生显着变化,并且它们肯定不会始终与同一查询的桌面结果相匹配。大多数谷歌 SEO 对其移动搜索结果的真实情况了解不多,因为大多数谷歌 SEO 报告工具仍然主要关注桌面结果,即使谷歌已切换到移动优先。
同样,谷歌搜索引擎优化工具通常只报告一个位置的排名——他们的服务器位置——而不是能够从不同的位置进行测试。
好的谷歌搜索引擎优化可以解决这个问题的唯一方法是使用像 MobileMoxie SERP 测试这样的工具来检查用户可能搜索的所有位置的热门关键字的排名。虽然这款免费工具一次只能提供一个位置的结果,但订阅者可以根据服务区域半径或上传的地址 CSV,在多个位置测试搜索结果。该工具与 Google 表格集成,并与 Data Studio 连接,以帮助进行谷歌搜索引擎优化报告,但 API 也可用,用于更深入地集成内容编辑工具、仪表板以及在其他谷歌搜索引擎优化工具中使用。
结论
在 MozCon 2017 上,我表达了我的信念,即移动优先索引的影响需要重新解释“移动”、“第一”和“索引”这三个词。在移动优先索引的上下文中重新定义,这些词应理解为“便携”、“首选”和“信息组织”。转向基于 Fraggle 的索引的潜力以及最近对 SERP 的更改,尤其是在过去一年中,似乎肯定证明了这一理论的准确性。尽管他们已经进行了两年多的工作,但现在对 SERP 的更改似乎正在更快地推出,并且使 SERP 与三四年前的情况相比变得面目全非。
在这篇文章中,我们将谷歌 SEO 的 Fraggles 和基于 Fraggle 的索引描述为一种理论,该理论推测移动优先索引变化的真实性质,索引本身 – 以及索引单位 – 如何改变以适应更快和基于知识图谱的更细致的信息组织,而不是简单的链接和 URL。我们介绍了 Fraggles 和基于 Fraggle 的索引是如何工作的,它与 JavaScript 和 PWA 的关系,以及谷歌 SEO 可以采取什么策略来利用它在搜索结果中增加曝光率,以及他们如何更新他们的成功跟踪以说明所有影响移动搜索结果的变量。
谷歌 SEO 需要考虑机遇并改变我们看待整体索引策略和整个工作的方式。如果谷歌围绕知识图谱组织索引,那么谷歌就可以更容易地在“相关搜索”轮播中不断提及知识图谱的附近节点、知识图谱中的链接以及 PAA 中的主题。这也可能让人更容易相信特色片段只是经过审查(通过 Google 的点击众包)以包含在知识图谱中或作为参考的信息片段。
Fraggles 和 Fraggled 索引重新构建了向移动优先索引的转换,这意味着谷歌搜索引擎优化和谷歌搜索引擎优化工具公司需要开始考虑移动优先——即他们信息的可移植性。虽然页面和域可能仍然带有强烈的排名信号,但 SERP 中的所有变化似乎都不太关注整个页面,而更多地关注页面的各个部分,类似于精选片段、PAA 和一些相关搜索中出现的那些. 如果谷歌更多地关注窗口内容并成为“答案引擎”而不是“搜索引擎”,那么这很符合他们声明的身份,以及他们建立一个更高效、可持续的国际引擎的愿望。
谷歌 SEO 还需要找到更好地为用户服务的方法,方法是更多地关注移动 SERP 的真实情况,以及它对真实用户的影响有多大。虽然 Google 可能不会将最小的可排名单位称为 Fraggles,但我们称之为 Fraggles,我们认为它们对 google SEO 的未来至关重要。



