
词汇大小和差异是数学和定性语言学的语义和语言概念。
例如,希普斯定律认为文章的长度和词汇量是相关的。然而,在某个阈值之后,相同的单词继续出现,而不会提高词汇量。
Word2Vec使用连续词包(CBOW)和跳过语法来理解本地上下文相关的词及其彼此之间的距离。同时,GloVe尝试在上下文窗口中使用矩阵分解。
齐普夫定律是希普斯定律的补充理论。它指出,最频繁和第二频繁的单词之间有一个固定的百分比差异。
统计自然语言处理中还有其他分布语义学和语言学理论。
但“词汇比较”是搜索引擎理解“话题性差异”、“文档的主要主题”或“文档的总体专业知识”的基本方法
谷歌的Paul Haahr表示,它将“查询词汇表”与“文档词汇表”进行了比较
大卫·C·泰勒(David C.Taylor)和他的上下文域设计涉及向量搜索中的某些词向量,以查看哪个文档和哪个文档小节更关注什么,因此搜索引擎可以基于搜索查询修改对文档进行排序和重新排序。
比较搜索引擎结果页面上排名网页之间的词汇差异(
SERP)帮助搜索引擎优化专家了解与竞争对手相比,他们跳过了哪些上下文、并发词和词接近度。
查看文档中的上下文差异很有帮助。
在本指南中,Python编程语言用于在Google上搜索并获取SERP项(片段),以抓取它们的内容、标记并将它们的词汇表相互比较。

如何将排名Web文档的词汇表与Python进行比较?
为了比较排名web文档的词汇表(使用Python),下面列出了使用的Python编程语言库和包。
- Googlesearch是一个Python包,用于使用查询、区域、语言、结果数、请求频率或安全搜索过滤器执行Google搜索。
- URLlib是一个Python库,用于解析指向netloc、scheme或路径的URL。
- 请求(可选)是获取SERP项目(片段)的标题、描述和链接。
- Fake_useragent是一个Python包,用于使用Fake和随机用户代理来防止429个状态代码。
- 广告工具用于抓取Google查询搜索结果中的URL,以获取正文文本,进行文本清理和处理。
- Pandas对数据进行调整和聚合,以进一步分析SERP上文档的分布语义。
- 自然语言工具包用于标记文档内容,并使用英语停止词删除停止词。
- 集合使用“计数器”方法计算单词的出现次数。
- 字符串是一个Python模块,它调用列表中的所有标点符号来清除标点符号。
比较Vocabu的步骤是什么
网页之间的大小和内容?
下面列出了比较排名网页之间词汇大小和内容的步骤。
- 导入必要的Python库和包,以检索和处理网页的文本内容。
- 执行Google搜索以检索SERP上的结果URL。
- 抓取URL以检索包含其内容的正文文本。
- 在NLP方法中标记网页内容以进行文本处理。
- 删除停止词和标点符号,以便更好地进行干净的文本分析。
- 计算网页内容中出现的单词数。
- 构建一个Pandas数据框架,以便进一步更好地进行文本分析。
- 选择两个URL,并比较它们的词频。
- 比较所选URL的词汇大小和内容。
1.导入必要的Python库和包,用于检索和处理网页的文本内容
使用“from”和“Import”命令和方法导入必要的Python库和包。
从googlesearch导入搜索
来自urllib。解析导入urlparse
进口请求
从fake_useragent导入useragent
将广告工具导入为adv
进口熊猫作为pd
来自nltk。标记化导入word_tokenize
导入nltk
从集合导入计数器
来自nltk。语料库导入停止词
导入字符串
nltk.download()
仅当您第一次使用nltk时,才使用“nltk.download”。下载所有语料库、模型和软件包。它将打开一个窗口,如下所示。
 作者截图,2022年8月
作者截图,2022年8月
不时刷新窗口;如果一切都是绿色的,请关闭窗口,以便代码编辑器上运行的代码停止并完成。
如果您没有上面的一些模块,请使用“pip安装”方法将它们下载到本地机器。如果您有一个封闭环境项目,请使用Python中的虚拟环境。
2.执行Google搜索以检索搜索引擎结果页面上的结果URL
执行Google se
要检索SERP项上的结果URL,请在“搜索”对象中使用for循环,该对象来自“Googlesearch”包。
serp_item_url=[]
对于搜索中的i(“搜索引擎优化”,num=10,start=1,stop=10,pause=1,lang=“en”,country=“us”):
serp_item_url.append(i)
印刷品(一)
以上代码块的说明如下:
- 创建一个空列表对象,如“serp_item_url”
- 在“搜索”对象中启动一个for循环,该循环说明查询、语言、结果数、第一个和最后一个结果以及国家限制。
- 将所有结果附加到“serp_item_url”对象,该对象包含一个Python列表。
- 打印您从Google SERP检索到的所有URL。
您可以在下面看到结果。
上面给出了查询“搜索引擎优化”的排名URL。
下一步是解析这些URL以进行进一步清理。
因为如果结果涉及“视频内容”,如果他们没有长视频描述或太多评论(这是一种不同的内容类型),就不可能执行健康的文本分析。
3.从结果网页中清除视频内容URL
要清除视频内容URL,请使用下面的代码块。
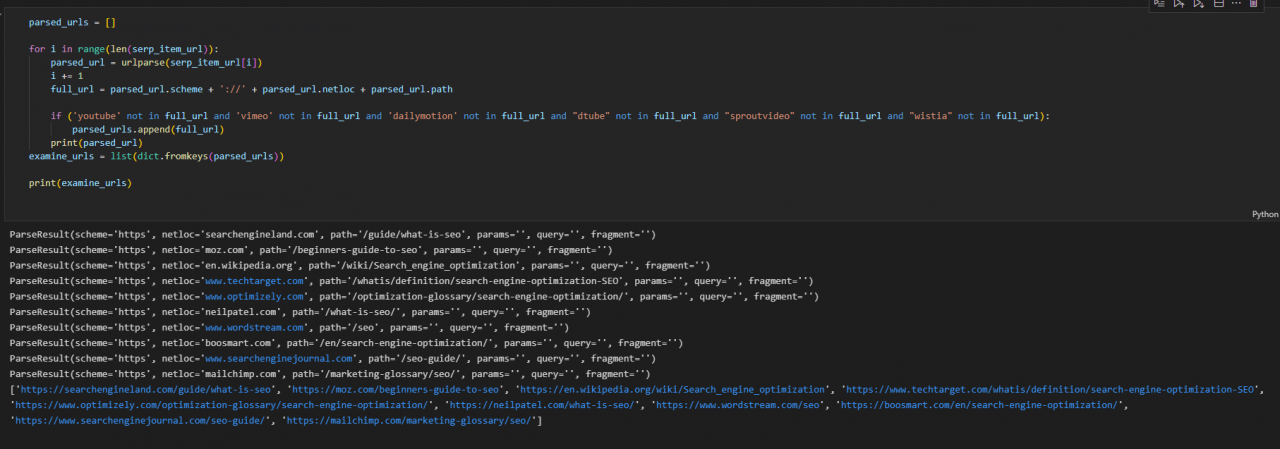
parsed_URL=[]
对于范围内的i(len(serp_item_url)):
parsed_url=urlparse(serp_item_url[i])
i+=1
full_url=parsed_url。scheme+’:\/“+parsed_url。netloc+parsed_url.path
如果(’youtube’不在full_url中,’vimeo’不在full_url和’dailymotion’不在full_url,而“dtube”不在full_url中,而“sproutvideo”不在full_url,而“wistia”不在full_url中):
parsed_url.append(full_url)
视频搜索引擎,如
如YouTube、Vimeo、Dailymotion、Sproutvideo、Dtube和Wistia,如果它们出现在结果中,将从结果URL中清除。
您可以对您认为会降低分析效率的网站使用相同的清理方法,或者使用自己的内容类型破坏结果。
例如,Pinterest或其他可视化网站可能不需要检查竞争文档之间的“词汇大小”差异。
以上代码块说明:
- 创建一个对象,如“parsed_url”
- 在检索结果URL计数的长度范围内创建for循环。
- 使用“urlparse”从“URLlib”解析URL
- 通过增加“i”的计数进行迭代
- 通过联合“scheme”、“netloc”和“path”检索完整URL
- 使用“if”语句中的条件以及要清理的域的“和”条件执行搜索。
- 使用“dict.fromkeys”方法将它们放入列表。
- 打印要检查的URL。
您可以在下面看到结果。
 作者截图,2022年8月
作者截图,2022年8月
4.抓取已清理的检查URL以检索其内容
抓取已清理的检查URL,以便使用广告工具检索其内容。
您也可以使用带有for循环和列表附加方法的请求,但advertools在爬行和创建具有结果输出的数据帧时速度更快。
通过请求,您可以手动检索并合并所有“p”和“heading”元素。
adv.crawl(检查URL,output_file=“检查URL.jl”,
follow_ links=False,
custom_settings={“USER_AGENT”:UserAgent().random,
“LOG_FILE”:“examine_urls.LOG”,
“爬网延迟”:2})
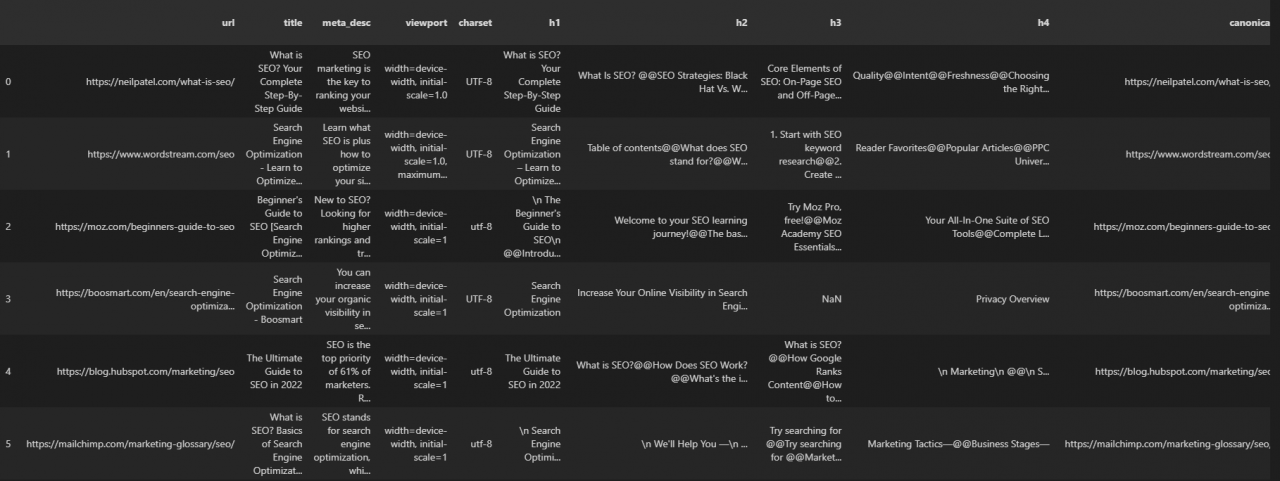
crawled_df=pd.read_json(“examine_urls.jl”,lines=True)
crawled_df
以上代码块说明:
- 使用“adv.crawl”对“examine_url”对象进行爬网。
- 为扩展名为“jl”的输出文件创建路径,该路径比其他路径小。
- 使用“follow_links=false”仅对列出的URL停止爬网。
- 如果某些URL不响应爬网请求,请使用自定义设置来声明“随机用户代理”和爬网日志文件。使用爬网延迟配置以防止429状态代码的可能性。
- 使用pandas“read_json”和“lines=True”参数读取结果。
- 调用“crawled_df”,如下所示。
您可以在下面看到结果。
 作者截图,2022年8月
作者截图,2022年8月
您可以看到我们的结果URL及其所有页面搜索引擎优化元素,包括响应标题、响应大小和结构化数据信息。
5.将网页的内容标记化,以便在NLP方法中进行文本处理
网页内容的标记化需要选择广告工具爬网输出的“body_text”列,并使用NLTK中的“word_tokenize”。
crawled_df[“body_text”][0]
上面的代码行调用其中一个结果页面的全部内容,如下所示。
 作者截图,2022年8月
作者截图,2022年8月
要标记这些句子,请使用下面的代码块。
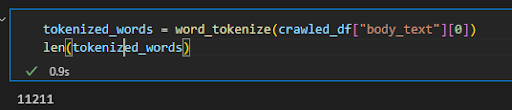
tokenized_words=word_tokenize(crawled_df[“body_text”][0])
len(标记化单词)
我们标记了第一个文档的内容,并检查它有多少单词。
 作者截图,2022年8月
作者截图,2022年8月
我们为查询“搜索引擎优化”标记的第一个文档有11211个单词。和样板内容
包括在该号码中。
6.从语料库中删除标点符号和停止词
删除标点符号和停止词,如下所示。
stop_words=set(stopwords.words(“英语”))
tokenized_words=[如果不是stop_word中的word.lower()和不是字符串中的words.lowers(),则在tokenize_word斯中逐字翻译]
len(标记化单词)
以上代码块说明:
- 创建一个包含“stopwords.words(“英语”)的集合,以包括英语中的所有stopword。Python集合不包含重复值;因此,我们使用集合而不是列表来防止任何冲突。
- 对“if”和“else”语句使用列表理解。
- 使用“lower”方法将“And”和“to”类型的单词与“stop words”列表中的小写版本进行适当比较。
- 使用“字符串”模块并包括“标点符号”。这里需要注意的是,字符串模块可能不包括您可能需要的所有标点符号。对于这些情况,创建您自己的标点列表,并使用regex和“regexsub”将这些字符替换为空格
- 或者,要删除标点符号或其他一些非字母和数字值,可以使用Python字符串的“isalnum”方法。但是,基于短语,它可能会给出不同的结果。例如,“isalnum”将删除“关键字相关”等词,因为该词中间的“-”不是字母数字。但是,这是一条线。标点符号不会删除它,因为“关键字相关”不是标点符号,即使“-”是。
- 测量新列表的长度。
符号化单词列表的新长度为“5319”。它显示了几乎一半的do词汇
文档由停止词或标点符号组成。
这可能意味着只有54%的单词是上下文的,其余的是功能性的。
7.统计网页内容中出现的单词数
为了计算语料库中单词的出现次数,“集合”模块中的“计数器”对象如下所示。
counted_tokenized_words=计数器(tokenizedwords)
counts_of_words_df=pd.DataFrame.from_dict(
counted_tokenized_words,orient=“index”).reset_index()
counts_of_words_df。sort_values(按=0,升序=False,就地=True)
counts_of_words_df.head(50)
代码块的解释如下。
- 创建一个变量,如“counted_tokenized_words”,以包含计数器方法结果。
- 使用Pandas中的“DataFrame”构造函数从标记化和清理文本的计数器方法结果构造新的数据帧。
- 使用“from_dict”方法,因为“Counter”给出一个字典对象。
- 使用“sort_values”和“by=0”表示基于行进行排序,“ascending=False”表示将最高值放在顶部。“Inpace=True”用于使新排序版本永久化。
- 使用pandas的“head()”方法调用前50行,以检查数据帧的第一个外观。
您可以在下面看到结果。
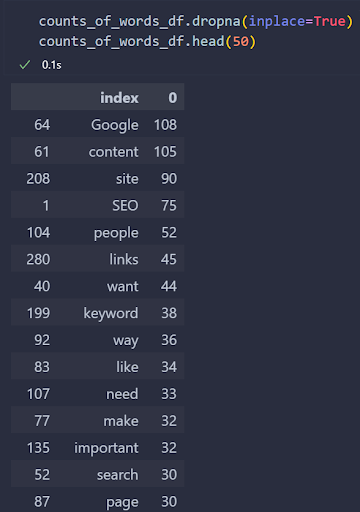 作者截图,2022年8月
作者截图,2022年8月
我们在结果中没有看到停止词,但仍保留了一些有趣的标点符号。
发生这种情况是因为有些网站出于相同的目的使用不同的字符,如大引号(智能引号)、单引号和双引号。
字符串模块的“函数”模块不涉及
ose。
因此,为了清理数据帧,我们将使用自定义lambda函数,如下所示。
removed_curly_quotes=“”“”“
counts_of_words_df[“索引”]=counts_ of_words_df[“索引”]。应用(lambda x:float(“NaN”),如果x在removed_curly_quotes中,否则为x)
counts_of_words_df.dropna(就地=真)
counts_of_words_df.head(50)
代码块说明:
- 创建了一个名为“removed_curly_quotes”的变量,以包含卷曲单引号、双引号和直双引号。
- 使用pandas中的“应用”函数检查所有列是否具有这些可能的值。
- 将lambda函数与“float”(“NaN”)一起使用,以便我们可以使用熊猫的“dropna”方法。
- 使用“dropna”删除替换特定花引号版本的任何NaN值。添加“inplace=True”以永久删除NaN值。
- 调用dataframe的新版本并检查它。
您可以在下面看到结果。
作者截图,2022年8月
我们在“搜索引擎优化”相关排名web文档中看到了最常用的词。
使用Panda的“绘图”方法,我们可以很容易地将其可视化如下。
counts_of_words_df.head(20)。绘图(kind=“bar”,x=“index”,orientation=“vertical”,figsize=(15,10),xlabel=“Tokens”,ylabel=“Count”,colormap=“viridis”,table=False,grid=True,fontsize=15,rot=35,position=1,title=“带有穿孔的网站内容的标记计数”,legend=True)。图例(〔“标记”〕,loc=左下角,prop={“大小”:15})
以上代码块说明:
- 使用head方法查看第一个有意义的值,以获得清晰的可视化效果。
- 使用带有“kind”属性的“plot”可以获得“条形图”
- 将“x”轴与包含单词的列放在一起。
- 我们
e方向属性用于指定打印方向。 - 使用指定高度和宽度的元组确定figsize。
- 为x轴和y轴名称放置x和y标签。
- 确定具有“viridis”等构造的颜色图
- 确定字体大小、标签旋转、标签位置、打印标题、图例存在、图例标题、图例位置和图例大小。
熊猫数据帧绘图是一个广泛的主题。如果您想使用“Plotly”作为Pandas可视化后端,请查看新闻搜索引擎优化热门话题的可视化。
您可以在下面看到结果。
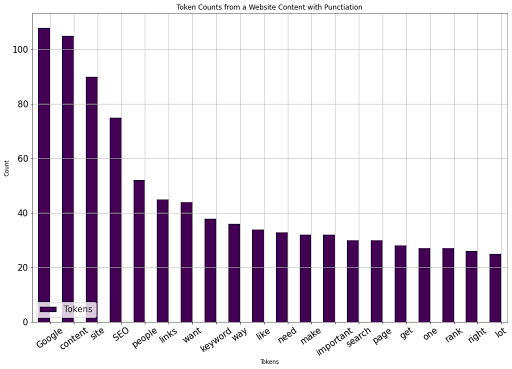 作者图片,2022年8月
作者图片,2022年8月
现在,我们可以选择第二个URL来开始比较词汇大小和单词出现率。
8.选择第二个URL以比较词汇大小和单词出现情况
要将以前的SEO内容与竞争的web文档进行比较,我们将使用SEJ的SEO指南。您可以在第二篇文章中看到到目前为止所遵循步骤的压缩版本。
def tokenize_visualize(文章:int):
stop_words=set(stopwords.words(“英语”))
removed_curly_quotes=“”“”“
tokenized_words=word_tokenize(crawled_df[“body_text”][文章])
打印(“标记化单词数:”,len(标记化单词))
tokenized_words=[单词
如果不是单词,则为tokenized_words中的单词。stop_words和word中的lower()。lower()不在字符串中。标点符号和单词。lower()不在removed_curly_quotes中]
打印(“删除打孔和停止字后标记化字的计数:”,len(标记化字))
counted_tokenized_words=计数器(tokenizedwords)
counts_of_words_df=pd.DataFrame.from_dict(
counted_tokenized_words,orient=“index”).reset_index()
counts_of_words_df。sort_values(按=0,升序=False,就地=True)
words_df[“索引”]=counts_of_words_ df[“索引”]。应用(lambda x:float(“NaN”),如果x在removed_curly_quotes中,否则为x)
counts_of_words_df.dropna(就地=真)
counts_of_words_df.head(20)plot(kind=“bar”,
x=“索引”,
方向=“垂直”,
figsize=(15,10),
xlabel=“代币”,
ylabel=“计数”,
colormap=“viridis”,
表=假,
网格=真,
fontsize=15,
rot=35,
位置=1,
title=“使用打孔的网站属性的令牌计数”,
图例=真)。图例([“标记”],
loc=“左下方”,
属性={“大小”:15})
我们收集了用于标记化、删除停止词、打孔、替换卷曲引号、计算单词、数据帧构造、数据帧排序和可视化的所有信息。
下面,您可以看到结果。
 作者截图,2022年8月
作者截图,2022年8月
SEJ文章排名第八。
tokenize_visualize(8)
数字8意味着它在爬网输出数据帧中排名第八,相当于SEJ的SEO文章。您可以在下面看到结果。
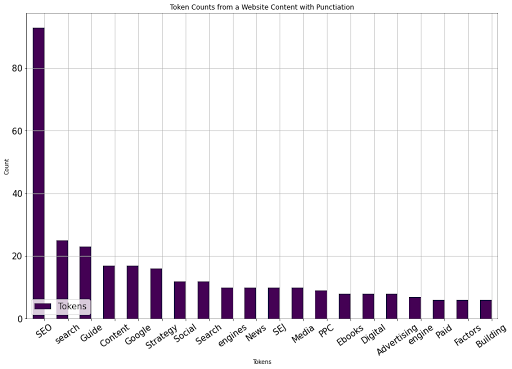 作者图片,2022年8月
作者图片,2022年8月
我们看到,SEJ SEO文章和其他竞争SEO文章之间使用最多的20个词有所不同。
9.创建一个自定义函数,以自动进行单词出现计数和词汇差异可视化
使用Python自动化任何SEO任务的基本步骤是将所有步骤和必要条件包装在具有不同可能性的特定Python函数下。
下面将看到的函数有一个条件语句。如果您传递单个文章,它将使用单个可视化调用;对于多个子图,它根据子图计数创建子图。
def tokenize_visualize(文章:列表,文章:int=None):
如果文章:
stop_words=set(stopwords.words(“英语”))
removed_curly_quotes=“”“”“
tokenized_words=word_tokenize(crawled_df[“body_text”][文章])
打印(“标记化单词数:”,len(标记化单词))
tokenized_words=[如果不是stop_word中的word.lower()和word.lower()不在string.标点符号中,并且word.lower()未在removed_curly_quotes中,则在tokenize_words中逐字输入]
打印(“删除打孔和停止字后标记化字的计数:”,len(标记化字))
counted_tokenized_words=计数器(tokenizedwords)
counts_of_words_df=pd.DataFrame.from_dict(
counted_tokenized_words,orient=“index”).reset_index()
counts_of_words_df。sort_values(按=0,升序=False,就地=True)
words_df[“索引”]=counts_of_words_ df[“索引”]。应用(lambda x:float(“NaN”),如果x在removed_curly_quotes中,否则为x)
counts_of_words_df.dropna(就地=真)
counts_of_words_df.head(20)plot(kind=“bar”,
x=“索引”,
方向=“垂直”,
figsize=(15,10),
xlabel=“代币”,
ylabel=“计数”,
colormap=“viridis”,
表=假,
网格=真,
fontsize=15,
rot=35,
位置=1,
title=“使用打孔的网站属性的令牌计数”,
图例=真)。图例([“标记”],
loc=“左下方”,
属性={“大小”:15})
如果文章:
source_names=[]
对于范围内的i(len(文章)):
source_name=crawled_df[“url”][文章[i]]
打印(source_name)
source_name=urlparse(source_ name)
打印(source_name)
source_name=source_ name.netloc
打印(source_name)
source_names.append(source_ name)
全局dfs
dfs=[]
对于文章中的i:
stop_words=set(stopwords.words(“英语”))
removed_curly_quotes=“”“”“
tokenized_words=word_tokenize(crawled_df[“body_text”][i])
打印(“标记化单词数:”,len(标记化单词))
tokenized_words=[如果不是stop_word中的word.lower()和word.lower()不在string.标点符号中,并且word.lower()未在removed_curly_quotes中,则在tokenize_words中逐字输入]
打印(“删除打孔和停止字后标记化字的计数:”,len(标记化字))
counted_tokenized_words=计数器(tokenizedwords)
counts_of_words_df=pd.DataFrame.from_dict(
counted_tokenized_words,orient=“index”).reset_index()
counts_of_words_df。sort_values(按=0,升序=False,就地=True)
words_df[“索引”]=counts_of_words_ df[“索引”]。应用(lambda x:float(“NaN”),如果x在removed_curly_quotes中,否则为x)
counts_of_words_df.dropna(就地=真)
df_individual=counts_of_words_df
dfs.append(df_individual)
导入matplotlib。pyplot作为plt
图中,轴=plt。子批次(len(文章),1)
对于范围内的i(len(dfs)+0):
dfs[i]。总目(20)。绘图(ax=轴[i],kind=“bar”,
x=“索引”,
方向=“垂直
ical”,
figsize=(长度(物品)*10,长度(物品))*10,
xlabel=“代币”,
ylabel=“计数”,
colormap=“viridis”,
表=假,
网格=真,
fontsize=15,
rot=35,
位置=1,
title=f“{source_names[i]}令牌计数”,
图例=真)。图例([“标记”],
loc=“左下方”,
属性={“大小”:15})
为了保持文章的简洁,我不会对这些进行解释。不过,如果您查看我之前编写的SEJ和Python SEO教程,您会发现类似的包装器函数。
让我们使用它。
tokenize_visualize(文章=[1,8,4])
我们希望看到第一、第八和第四篇文章,并可视化它们的前20个单词及其出现情况;您可以在下面看到结果。
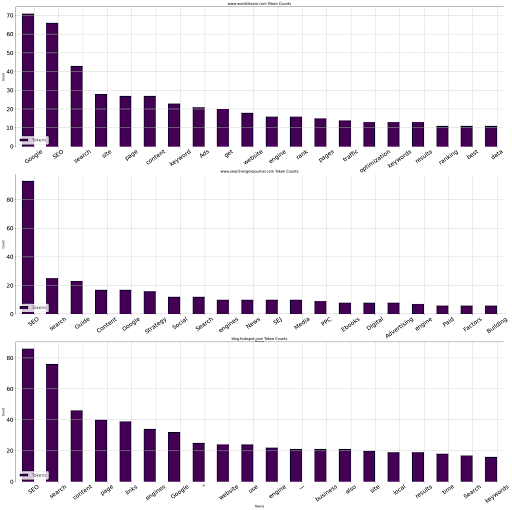 作者图片,2022年8月
作者图片,2022年8月
10.比较文档之间的唯一字数
多亏了pandas,比较文档之间的唯一字数非常容易。您可以检查下面的自定义函数。
def compare_unique_word_count(文章:列表):
source_names=[]
对于范围内的i(len(文章)):
source_name=crawled_df[“url”][文章[i]]
source_name=urlparse(source_ name)
source_name=source_ name.netloc
source_names.append(source_ name)
stop_words=set(stopwords.words(“英语”))
removed_curly_quotes=“”“”“
i=0
对于文章中的文章:
text=crawled_df[“body_text”][文章]
t
okenized_text=word_tokenize(文本)
tokenized_cleaned_text=[如果不是word,则在tokenized_text中逐字输入。如果不是words,则在stop_words中使用lower()。如果不是WORM,则在string中使用lower()。如果没有word,在removed_curly_quotes中使用标点符号。lower()
tokenized_cleanet_text_counts=计数器(tokenize_cleaned_text)
tokenized_cleanet_text_counts_df=pd.DataFrame。from_dict(tokenized_cleanet_text_counts,orient=“index”).reset_index()。重命名(columns={“index”:source_names[i],0:“Counts”})。sort_values(by=“Counts”,升序=False)
i+=1
打印(tokenized_cleanet_text_counts_df,“唯一字数:”,tokenized_CLANET_text_CONTS_df.nunique(),“总上下文字数:“,”tokenized_CLIANET_text_COLLTS_dfs[“计数]”。sum(),“总字数:”,len(tokenized_text))
compare_unique_word_count(文章=[1,8,4])
结果如下。
结果的底部显示了唯一值的数量,它显示了文档中唯一单词的数量。
www.wordstream。com计数
16谷歌71
82 SEO 66
186搜索43
228站点28
274第27页
… … …
510标记\/结构化1
1最近的1
514错误1
515底部1
1024 LinkedIn 1
[1025行x 2列]唯一字数:
www.wordstream。com 1025
第24条
数据类型:int64上下文总字数:2399总字数:
www.searchenginejournal。com计数
9 SEO 93
242搜索25
64指南23
40内容17
13谷歌17
.. … …
229行动1
228移动1
227敏捷1
226
32 1
465新闻1
[466行x 2列]唯一字数:
www.searchenginejournal。com 466
第16条
数据类型:int64上下文总字数:1019总字数:
blog.hubspot。com计数
166 SEO 86
160搜索76
32内容46
368第40页
327链接39
… … …
695想法1
697交谈1
698较早时1
699分析1
1326安全1
[1327行x 2列]唯一字数:
blog.hubspot。com 1327
第31条
数据类型:int64上下文总字数:3418总字数:
2399个非停止词和非标点上下文词中有1025个独特词。总字数为4918。
最常用的五个词是“谷歌”、“搜索引擎优化”、“搜索”、“网站”和“页面”,用于“Wordstream”。你可以看到其他数字相同的词。
11.比较SERP上文档之间的词汇差异
审核竞争文档中出现的独特词语有助于您了解文档在哪些方面更重要,以及它如何产生差异。
方法很简单:“集合”对象类型有一个“差异”方法来显示两个集合之间的不同值。
def audit_vocationary_difference(文章:列表):
stop_words=set(stopwords.words(“英语”))
removed_curly_quotes=“”“”“
全局dfs
全局源名称
source_names=[]
对于范围内的i(len(a
文章)):
source_name=crawled_df[“url”][文章[i]]
source_name=urlparse(source_ name)
source_name=source_ name.netloc
source_names.append(source_ name)
i=0
dfs=[]
对于文章中的文章:
text=crawled_df[“body_text”][文章]
tokenized_text=word_tokenize(文本)
tokenized_cleaned_text=[如果不是word,则在tokenized_text中逐字输入。如果不是words,则在stop_words中使用lower()。如果不是WORM,则在string中使用lower()。如果没有word,在removed_curly_quotes中使用标点符号。lower()
tokenized_cleanet_text_counts=计数器(tokenize_cleaned_text)
tokenized_cleanet_text_counts_df=pd.DataFrame。from_dict(tokenized_cleanet_text_counts,orient=“index”).reset_index()。重命名(columns={“index”:source_names[i],0:“Counts”})。sort_values(by=“Counts”,升序=False)
tokenized_cleanet_text_counts_df.dropna(inplace=True)
i+=1
df_individual=tokenized_cleanet_text_counts_df
dfs.append(df_individual)
全球词汇差异
词汇差异=[]
对于dfs中的i:
词汇表=set(i.iloc[:,0].to_list())
词汇_difference.append(词汇表)
打印(“出现在:”,source_names[0],“但不在:”、source_ names[1],“下面的单词:\n”,词汇差异[0]。差异(词汇差异[1]))
为了保持简洁,我不会逐一解释函数行,但基本上,我们在多篇文章中使用独特的词,并将它们相互比较。
您可以在下面看到结果。
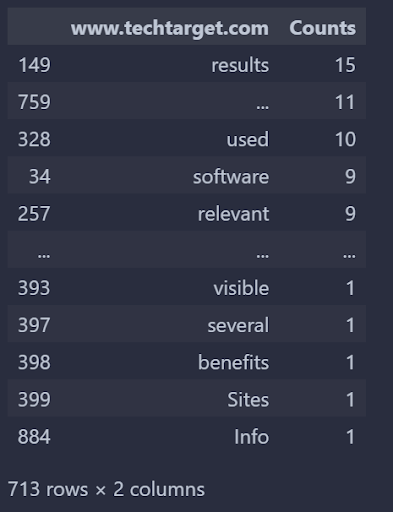
出现在:www.techtarget。com,但不在:moz。com如下:
 作者截图,2022年8月
作者截图,2022年8月
使用下面的自定义函数查看这些词在特定文档中的使用频率。
def unique_vocabulary_weight():
audit_vocationary_difference(文章=[3,1])
词汇差异列表=词汇差异df[0].to_list()
返回dfs[0][dfs[0]。iloc[:,0].isin(词汇差异列表)]
unique_vocabulary_weight()
结果如下。
 作者截图,2022年8月
作者截图,2022年8月
从TechTarget的角度来看,“搜索引擎优化”查询中,TechTarget和Moz之间的词汇差异如上所述。我们可以逆转它。
def unique_vocabulary_weight():
audit_vocationary_difference(文章=[1,3])
词汇差异列表=词汇差异df[0].to_list()
返回dfs[0][dfs[0]。iloc[:,0].isin(词汇差异列表)]
unique_vocabulary_weight()
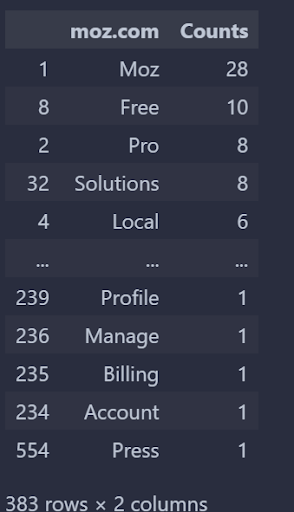
更改数字的顺序。从另一个角度检查。
 作者截图,2022年8月
作者截图,2022年8月
您可以看到,Wordstream有868个独特的单词没有出现在Boosmart上,上面给出了前五个和后五个单词的出现情况。
通过检查查询信息和网络,“加权频率”可以改进词汇差异审计。
但是,出于教学目的,这已经是一门繁重、详细和高级的Python、数据科学和SEO密集课程。
请参阅下一篇指南和教程。



