![使用 Python 进行竞争对手反向链接分析 [完整脚本]](https://www.adwebcloud.com/wp-content/uploads/2022/09/python-competitor-backlinks-628bb7e9cf5ac-sej-1520x800-19.png)
在我的上一篇文章中,我们使用来自 Ahrefs 的数据分析了我们的反向链接。
这一次,我们使用相同的 Ahrefs 数据源在分析中包括竞争对手的反向链接进行比较。
像上次一样,我们将网站反向链接的价值定义为质量和数量的产物。
质量是域权威(或 Ahrefs 的等效域评级),数量是引用域的数量。
同样,我们将在评估数量之前使用可用数据评估链接质量。
是时候编码了。
导入重新
导入时间
导入随机
导入熊猫作为pd
导入numpy作为np
导入日期
时间从日期时间导入timedelta
从plotnine导入*
导入matplotlib.pyplot作为plt
从pandas.api.types导入is_string_dtype
从pandas.api.types导入is_numeric_dtype
导入uritools
pd.set_option(‘display.max_colwidth’, None)
%matplotlib inline
root_domain = ‘johnsankey.co.uk’
hostdomain = ‘www.johnsankey.co.uk’
主机名 = ‘johnsankey’
full_domain = ‘https://www.johnsankey .co.uk’
target_name = ‘约翰·桑基’
数据导入和清理
我们设置了文件目录,在一个文件夹中读取多个 Ahrefs 导出的数据文件,这比单独读取每个文件更快、更少无聊、更高效。
尤其是当你有超过 10 个时!
ahrefs_path = ‘数据/’
OS 模块的 listdir() 函数允许我们列出子目录中的所有文件。
ahrefs_filenames = os.listdir(ahrefs_path)
ahrefs_filenames.remove(‘.DS_Store’)
ahrefs_filenames
现在列出的文件名如下:
[‘www.davidsonlondon.com–refdomains-subdomain__2022-03-13_23-37-29.csv’,
‘www.stephenclasper.co.uk–refdomains-subdoma__2022-03-13_23-47-28.csv’,
‘ www.touchedinteriors.co.uk–refdomains-subdo__2022-03-13_23-42-05.csv’,
‘www.lushinteriors.co–refdomains-subdomains__2022-03-13_23-44-34.csv’,
‘www. kassavello.com–refdomains-subdomains__2022-03-13_23-43-19.csv’,
‘www.tulipinterior.co.uk–refdomains-subdomai__2022-03-13_23-41-04.csv’,
‘www.tgosling。 com–refdomains-subdomains__2022-03-13_23-38-44.csv’,
‘www.onlybespoke.com–refdomains-subdomains__2022-03-13_23-45-28.csv’,
‘www.williamgarvey.co.uk- -refdomains-subdomai__2022-03-13_23-43-45.csv’,
‘www.hadleyrose.co.uk–refdomains-subdomains__2022-03-13_23-39-31.csv’,
‘www.davidlinley.com–refdomains-subdomains__2022-03-13_23-40-25.csv’,
‘johnsankey.co.uk-refdomains-subdomains__2022-03-18_15-15-47.csv’]
列出文件后,我们现在将使用 for 循环单独读取每个文件,并将它们添加到数据帧中。
在读取文件时,我们将使用一些字符串操作来创建一个新列,其中包含我们正在导入的数据的站点名称。
ahrefs_df_lst = list()
ahrefs_colnames = list()
对于 ahrefs_filenames 中的文件名:
df = pd.read_csv(ahrefs_path + filename)
df[‘site’] = filename
df[‘site’] = df[‘site’].str.replace(‘www.’, ”, regex = False)
df[‘site’] = df[‘site’].str.replace(‘.csv’, ”, 正则表达式 = False)
df[‘site’] = df[‘site’].str.replace (‘-.+’, ”, 正则表达式 = True)
ahrefs_colnames.append(df.columns)
ahrefs_df_lst.append(df)
ahrefs_df_raw = pd.concat(ahrefs_df_lst)
ahrefs_df_raw

图片来自 Ahrefs,2022 年 5 月
现在我们在单个数据框中拥有来自每个站点的原始数据。下一步是整理列名并使它们更易于使用。
尽管可以通过自定义函数或列表理解来消除重复,但对于初学者 SEO Pythonistas 来说,这是一种很好的做法,并且更容易逐步了解正在发生的事情。正如他们所说,“重复是掌握之母”,所以开始练习吧!
竞争者_ahrefs_cleancols = ahrefs_df_raw竞争者_ahrefs_cleancols.columns = [
col.lower() 用于竞争者
_ahrefs_cleancols.columns 中的列]
replace(‘.’,’_’) 为竞争者_ahrefs_cleancols.columns 中的列]
竞争者_ahrefs_cleancols.columns = [col.replace(‘__’,’_’) 为竞争者_ahrefs_cleancols.columns 中的列]
竞争者_ahrefs_cleancols.columns = [col.replace( ‘(‘,”) for col incompetitor_ahrefs_cleancols.columns]
竞争者_ahrefs_cleancols.columns = [col.replace(‘)’,”) for col 在竞争者_ahrefs_cleancols.columns]
竞争者_ahrefs_cleancols.columns = [col.replace(‘%’,”) for col 在竞争者_ahrefs_cleancols.columns]
计数列和具有单值列(’project’)对于 groupby 和聚合操作很有用。
竞争对手_ahrefs_cleancols[‘rd_count’] = 1
竞争对手_ahrefs_cleancols[‘project’] = target_name
竞争者
_ahrefs_cleancols 图片来自 Ahrefs,2022 年 5 月
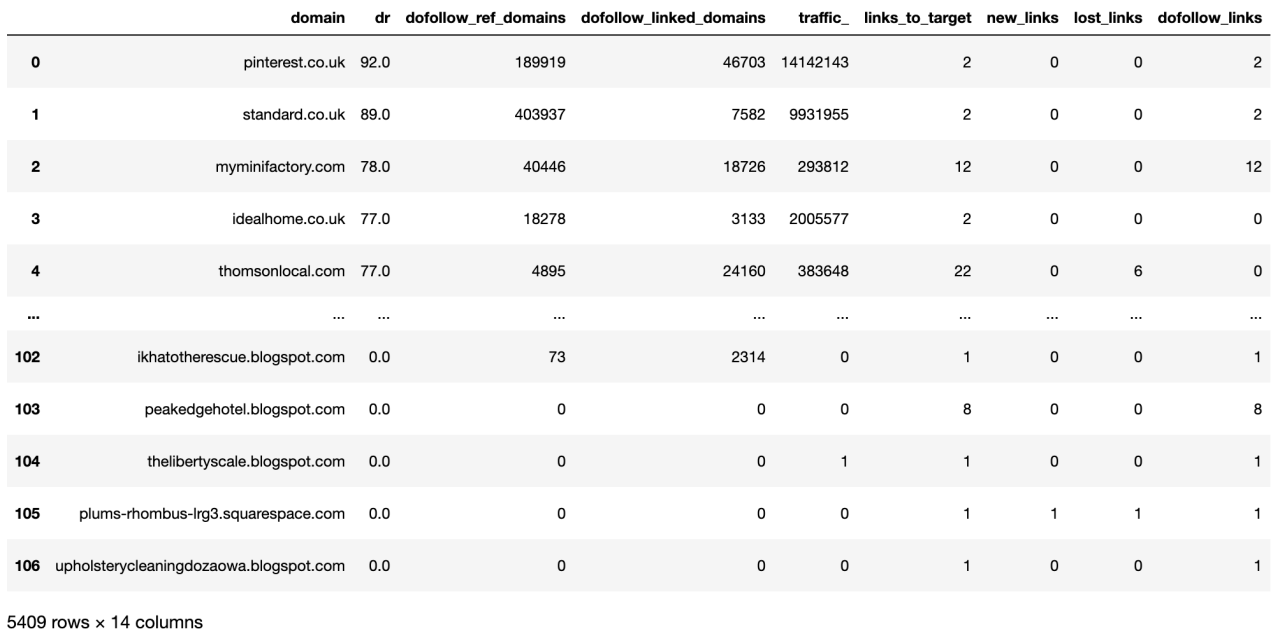
列已清理,所以现在我们将清理行数据。
竞争对手_ahrefs_clean_dtypes = 竞争对手_ahrefs_cleancols
对于引用域,我们将连字符替换为零并将数据类型设置为整数(即整数)。
这也将针对链接域重复。
竞争对手_ahrefs_clean_dtypes[‘dofollow_ref_domains’] = np.where(competitor_ahrefs_clean_dtypes[‘dofollow_ref_domains’] == ‘-‘,
0, 竞争对手
_ahrefs_clean_dtypes[‘dofollow_ref_domains’])
#linked_domains
竞争者_ahrefs_clean_dtypes[‘dofollow_linked_domains’] = np.where(competitor_ahrefs_clean_dtypes[‘dofollow_linked_domains’] == ‘-‘,
0, 竞争者
_ahrefs_clean_dtypes[‘dofollow_linked_domains’])
First seen 为我们提供了找到链接的日期点,我们可以将其用于时间序列绘图和导出链接年龄。
我们将使用 to_datetime 函数转换为日期格式。
# first_seen
竞争对手_ahrefs_clean_dtypes[‘first_seen’] = pd.to_datetime(competitor_ahrefs_clean_dtypes[‘first_seen’],
格式=’%d/%m/%Y %H:%M’)
竞争对手_ahrefs_clean_dtypes[‘first_seen’] = 竞争对手_ahrefs_clean_dtypes[‘first_seen’ ].dt.normalize()
竞争对手_ahrefs_clean_dtypes[‘month_year’] = 竞争对手_ahrefs_clean_dtypes[‘first_seen’].dt.to_period(‘M’)
要计算 link_age,我们只需从今天的日期中减去第一次看到的日期,然后将差值转换为数字。
# 链接年龄
竞争者_ahrefs_clean_dtypes[‘link_age’] = dt.datetime.now()-竞争者_ahrefs_clean_dtypes[‘first_seen’]
竞争者_ahrefs_clean_dtypes[‘link_age’] =竞争者_ahrefs_clean_dtypes[‘link_age’]
竞争者_ahrefs_clean_dtypes[‘link_age’] =竞争者_ahrefs_clean_dtypes[‘link_age’] .astype(int)
竞争对手_ahrefs_clean_dtypes[‘link_age’] = (competitor_ahrefs_clean_dtypes[‘link_age’]/(3600 * 24 * 1000000000)).round(0)
目标列帮助我们区分“客户”网站与竞争对手,这对以后的可视化很有用。
竞争者_ahrefs_clean_dtypes[‘target’] = np.where(competitor_ahrefs_clean_dtypes[‘site’].str.contains(‘johns’),
1, 0)
竞争者_ahrefs_clean_dtypes[‘target’] = 竞争者_ahrefs_clean_dtypes[‘target’].astype(‘category’ )
竞争者
_ahrefs_clean_dtypes 图片来自 Ahrefs,2022 年 5 月
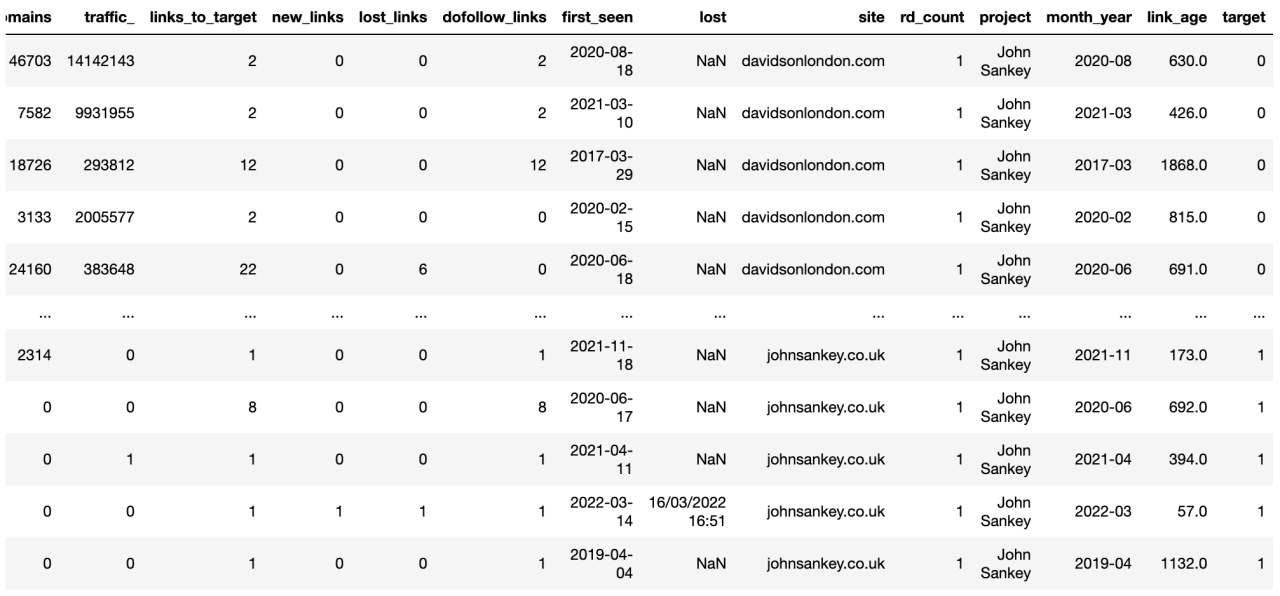
既然数据已经按照列标题和行值进行了清理,我们就可以开始分析了。
链接质量
我们从链接质量开始,我们将接受域评级 (DR) 作为衡量标准。
让我们首先通过使用 geom_bokplot 函数绘制分布来检查 DR 的分布属性。
comp_dr_dist_box_plt = (
ggplot(competitor_ahrefs_analysis.loc[competitor_ahrefs_analysis[‘dr’] > 0],
aes(x = ‘reorder(site, dr)’, y = ‘dr’, color = ‘target’)) +
geom_boxplot(alpha = 0.6) +
scale_y_continuous() +
主题(legend_position = ‘none’,
axis_text_x=element_text(rotation=90, hjust=1)
))
comp_dr_dist_box_plt.save(filename = ‘images/4_comp_dr_dist_box_plt.png’,
height=5, width=10, units = ‘in’, dpi=1000)
comp_dr_dist_box_plt
图片来自 Ahrefs,2022 年 5 月
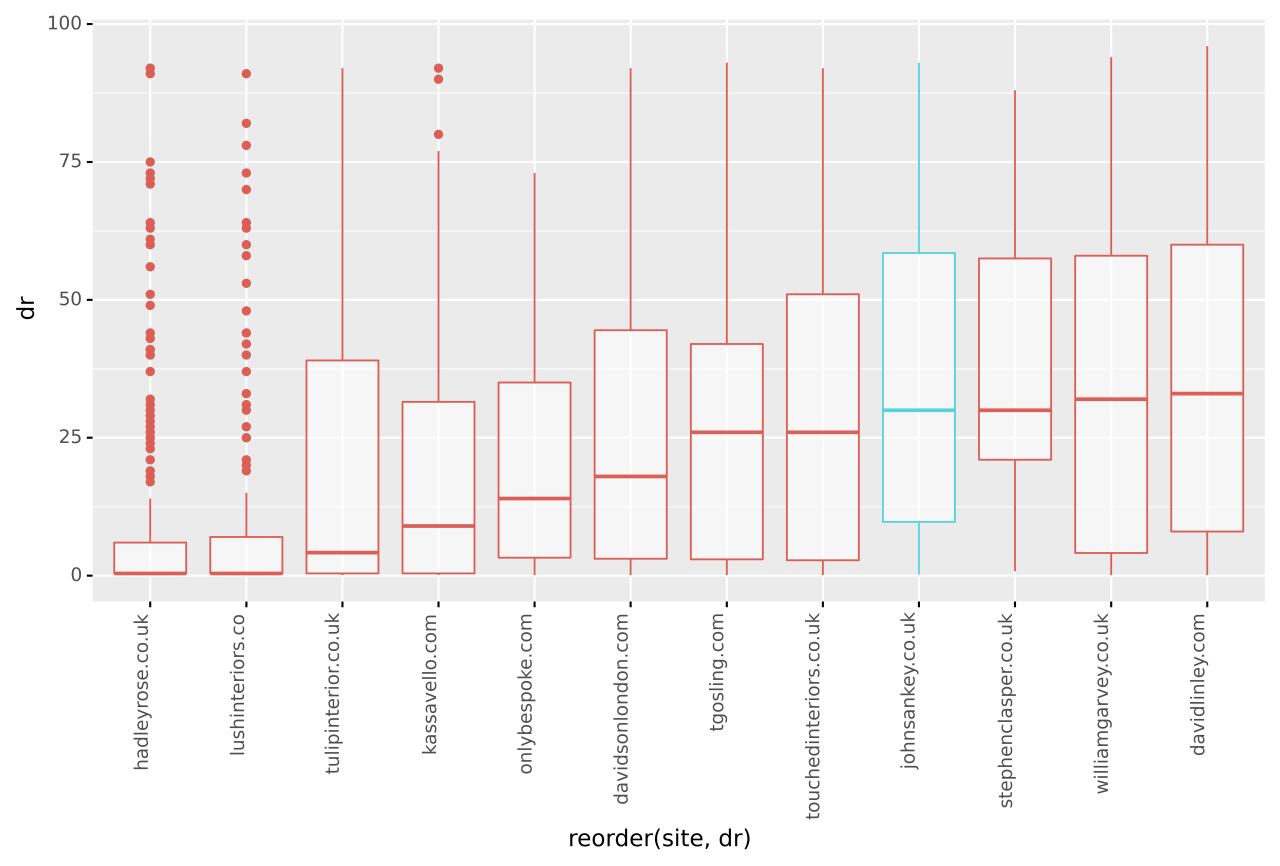
该图并排比较了网站的统计属性,最值得注意的是,四分位间距显示了大多数引用域在域评级方面的位置。
我们还看到 John Sankey 具有第四高的中值域评级,与其他网站的链接质量相比,效果很好。
与其他领域相比,William Garvey 拥有最多样化的 DR,这表明链接获取的标准稍微宽松一些。谁知道。
链接卷
这就是质量。来自引用域的链接量如何?
为了解决这个问题,我们将使用 groupby 函数计算引用域的运行总和。
竞争对手_count_cumsum_df = 竞争对手_ahrefs_analysis
竞争对手_count_cumsum_df = 竞争对手_count_cumsum_df.groupby([‘site’, ‘month_year’])[‘rd_count’].sum().reset_index()
扩展功能允许计算窗口随着行数的增加而增长,这就是我们实现运行总和的方式。
竞争对手_count_cumsum_df[‘count_runsum’] = 竞争对手_count_cumsum_df[‘rd_count’].expanding().sum()
竞争者
_count_cumsum_df 图片来自 Ahrefs,2022 年 5 月
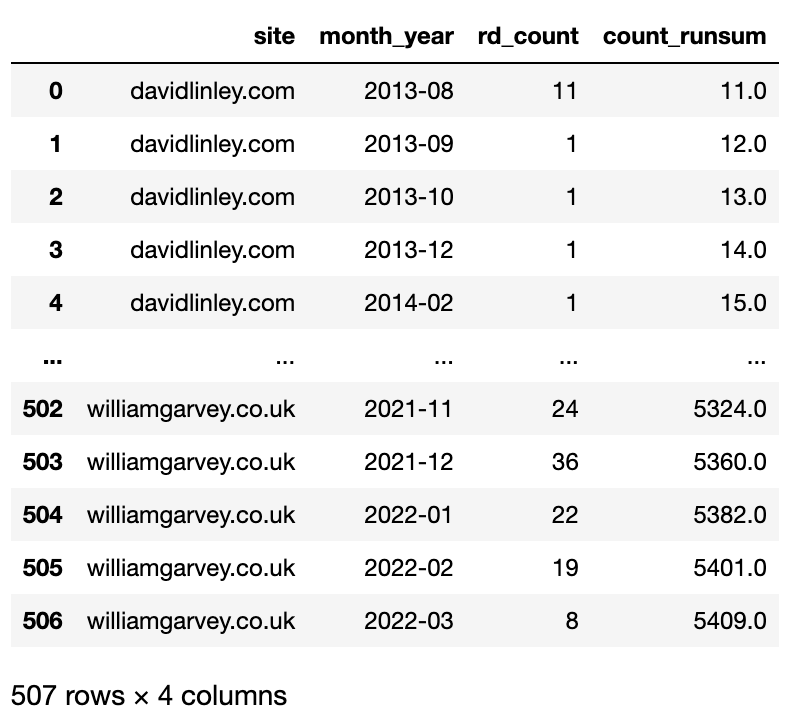
结果是一个包含站点、month_year 和 count_runsum(运行总和)的数据框,它采用完美的格式来提供图表。
竞争者计数累加plt = (
ggplot(竞争计数累加_df, aes(x = ‘month_year’, y = ‘count_runsum’,
group = ‘site’, color = ‘site’)) +
geom_line(alpha = 0.6, size = 2) +
labs(y = ‘引用域的运行总和’,x = ‘月份年份’) +
scale_y_continuous() +
scale_x_date() +
theme(legend_position = ‘right’,
axis_text_x=element_text(rotation=90, hjust=1)
))
竞争者_count_cumsum_plt.save(文件名=’images/5_count_cumsum_smooth_plt.png’,
高度=5,宽度=10,单位=’in’,dpi=1000)
竞争对手
_count_cumsum_plt 图片来自 Ahrefs,2022 年 5 月

该图显示了自 2014 年以来每个站点的引用域数量。
当每个站点开始获取链接时,我发现每个站点的不同起始位置非常有趣。
例如,William Garvey 一开始就有超过 5,000 个域名。我很想知道他们的公关公司是谁!
我们还可以看到增长率。例如,虽然 Hadley Rose 在 2018 年开始获取链接,但事情在 2021 年中期左右才真正起飞。
更多,更多,更多
你总是可以做更科学的分析。
例如,上述内容的一个直接和自然的扩展是结合质量(DR)和数量(体积),以便更全面地了解网站在场外 SEO 方面的比较。
其他扩展将是为您自己和您的竞争对手网站模拟那些引用域的质量,以查看哪些链接功能(例如链接内容的字数或相关性)可以解释您和您的竞争对手之间的可见性差异.
这个模型扩展将是这些机器学习技术的一个很好的应用。



